
前言
本文记录了在使用DirectIO对Loop设备与真实设备进行吞吐量对比测试时,遇到的异常情况。通过该异常情况,分析了Loop设备的工作原理。
Loop设备
/dev/loop设备在Linux中是一种伪设备,这种设备可以让文件如同块设备一般被访问,让普通文件可以像块设备被格式化文件系统,可以进行挂载。
Loop设备必须与一个现有的文件进行关联,如果文件中包含文件系统,那么这个文件就可以被挂载。
例如,查看当前系统空闲的Loop设备:
losetup -f
关联空闲设备loop1到一个现有文件test.img,格式化为ext4文件系统并挂载到./mnt目录下。
1 | losetup /dev/loop1 test.img |
DirectIO
直接IO是一种无缓冲的IO,对文件的读写操作不会经过操作系统内核中的文件缓存。内核文件缓存中提供的预读取、延迟写入等机制不一定适合所有应用场景,例如数据库通常有一套自身的缓存机制和落盘机制,如果没有能够绕过内核文件缓存的机制,就会存在双重缓存。DirectIO就提供了绕过内核文件缓存的方法。
在open文件的时候设置 O_DIRECT 标识就可以使用DirectIO。
1 |
|
DirectIO吞吐量对比
分别对真实设备和Loop设备进行吞吐量测试。
实验猜想:
真实设备的吞吐量会明显高于Loop设备。因为采用DirectIO都绕过内核缓存去设备中读取数据的情况下,Loop设备因为是关联的一个已存在的文件,会转化为对原镜像文件test.img的读取,在经过两层IO栈的情况下,吞吐量会低于直接读取真实设备。
吞吐量测试程序如下:
1 | fd = open(argv[1], O_RDONLY | O_DIRECT); |
使用该程序分别读取Loop设备中的文件./mnt/loop_file,真实设备中的文件./device_file。
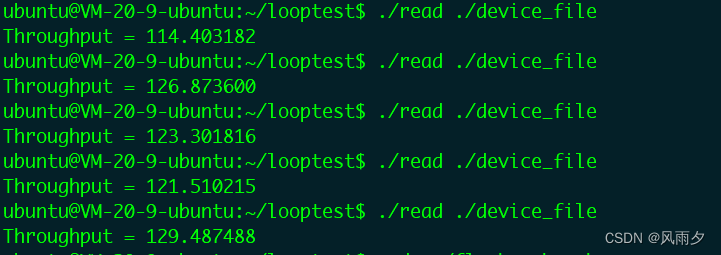
真实设备吞吐量如下图所示,在120左右:
Loop设备吞吐量如下图所示,在700左右:
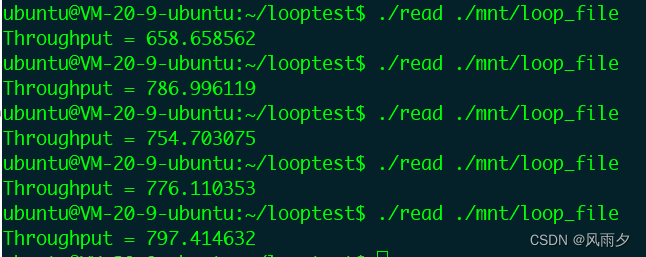
实验结果与猜想正好相反,Loop设备的吞吐量远大于真实设备。是什么原因造成了这种结果呢?
实验现象分析
Loop设备的吞吐量如此高,猜想它在设置O_DIRECT标识的情况下,还是使用了内核中的文件缓存,才会比真实设备快。通过如下两步进行验证:
- 查看测试程序执行前后,系统中cache大小的变化情况。
- 通过trace工具根据内核中函数调用栈,判断测试程序是走的buff IO分支还是direct IO分支。
cache大小分析
首先清空系统中的文件cache,清空后的buff/cache大小为213816KB。
1 |
|

执行Loop设备下的吞吐量测试程序,可以看到清空缓存后,第一次执行,吞吐量变低了,后续执行结果,又回到了高吞吐量。说明后续读取内容都命中了缓存,吞吐量变高。
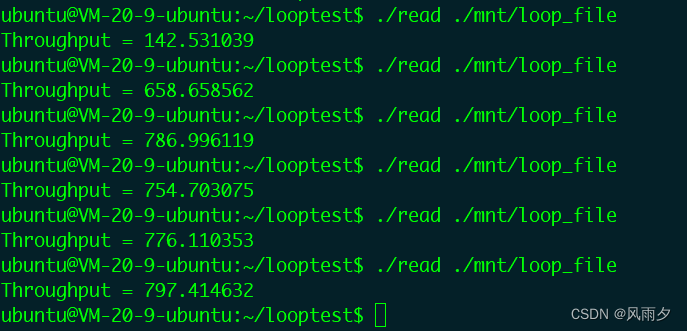
继续查看现在系统中的cache大小,变成了267688KB,增加了50M的大小。而我们读写的文件大小为40M,也很接近。

所以,在设置O_DIRECT标识的情况下对Loop设备中的文件进行读取,Loop设备还是使用了内核中的文件缓存。那么Loop设备具体是在哪里使用了缓存呢?
Loop设备读操作内核栈跟踪
猜想Loop设备的调用栈如下图所示,在这个调用栈里面如果Loop设备使用缓存,最可能就是在下图中两个橙色的文件缓存处。接下来我们对这个假设进行验证。
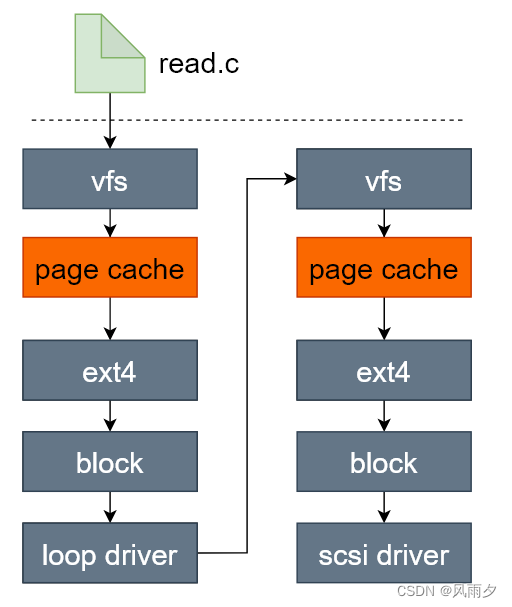
我们需要捕获到读取loop设备中文件的内核调用栈,才能验证上图是正确的。上图中经过了两次ext4文件系统,所以我们先跟踪一下ext4_file_read_iter函数,看一次read是否调用了两次该函数。
借助bcc,成功捕获到了两次ext4读取操作。如下图所示,第一次由read发起,第二次由loop1发起,而且第二次执行是由内核线程kthread执行的kthread work,很明显loop_queue_work是loop驱动设置的work回调函数。
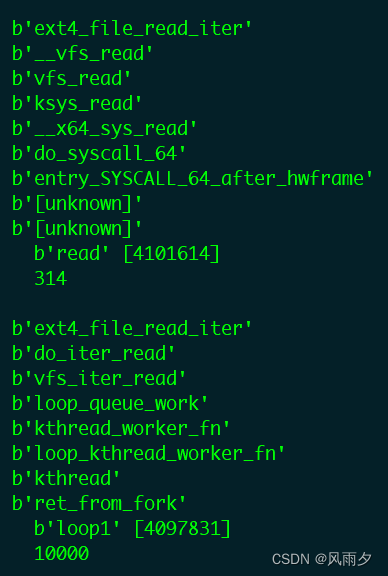
loop_queue_work由loop设备驱动初始化时设置的多请求队列函数操作集中的loop_init_request函数设置,过程如下图所示。当块层的请求队列进行请求派发时,就会唤醒worker,执行该函数。(/drivers/block/loop.c)

下面我们需要跟踪执行loop_queue_work的函数调用栈,查看第一段读操作的IO栈完整路径。
这次我们挂载loop驱动中负责处理块层多请求队列派发的request函数,即上图中的loop_queue_rq,调用栈如下图所示(自下向上)。
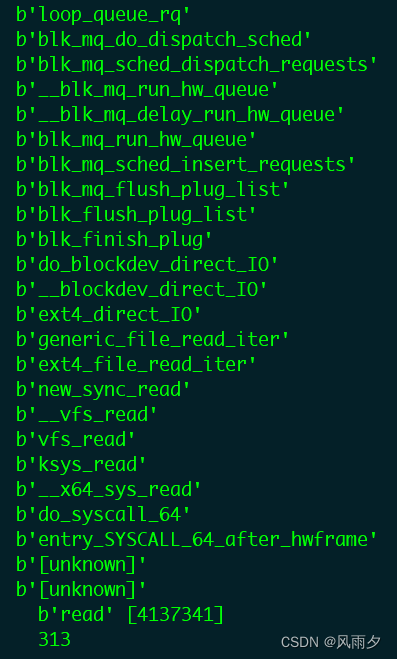
可以看到第一段IO栈由于设置了O_DIRECT标识的原因,确实没有使用内核文件缓存,执行了ext4_direct_IO分支。
块层一些函数的主要功能如下:
1 | blk_finish_plug : IO请求泄流(进程) |
loop_queue_rq最终会将work插入到worker队列中,并唤醒睡眠的 worker->task,此刻 worker 上 work 的 work->func 得以执行,此处就是执行loop_queue_work。
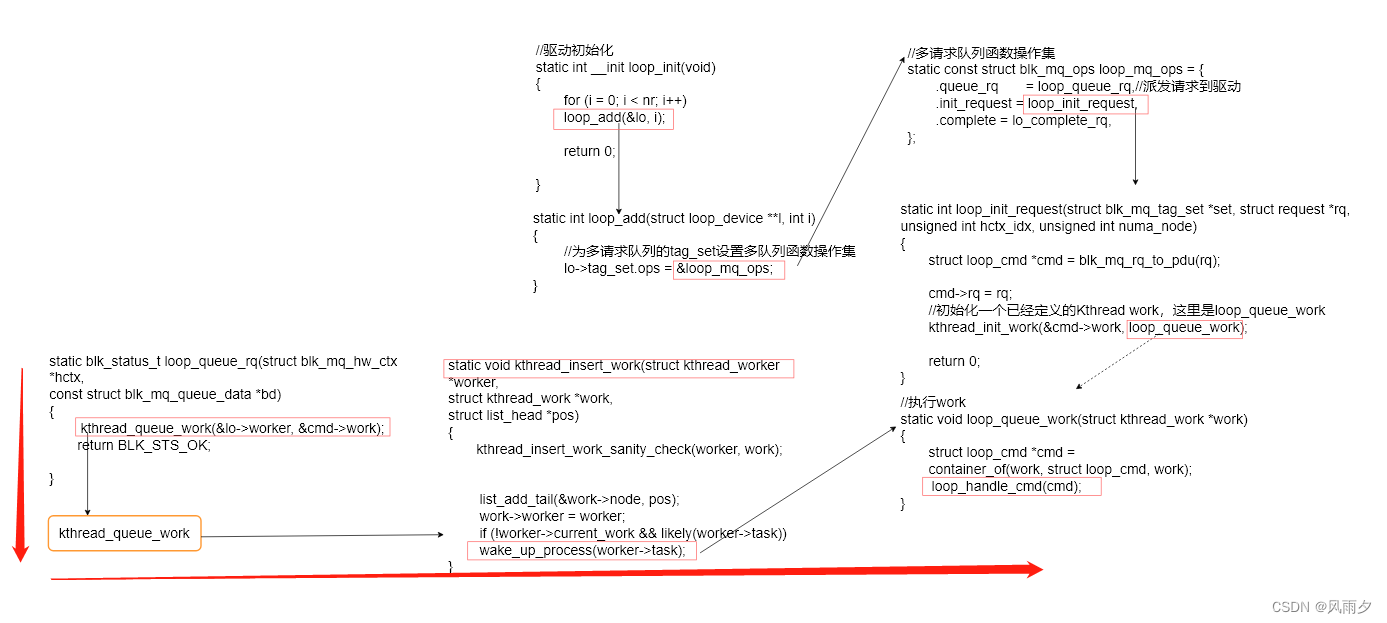
loop驱动如何处理请求
从下图loop1发起的第二次IO调用栈可以看到,loop驱动又将请求转发到了虚拟文件系统层,即函数vfs_iter_read。此时就是对loop设备所关联的镜像文件进行IO操作了。接下来我们验证一下,第二段IO操作是否使用了文件缓存。
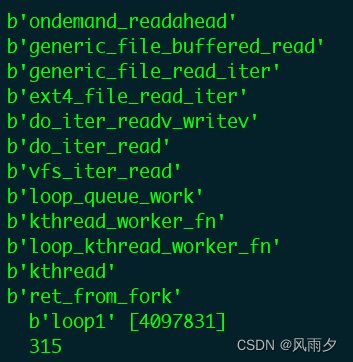
我们挑选缓存读中的负责预读窗口初始化的函数ondemand_readahead进行跟踪,结果如下图所示。
结果显示了generic_file_buffered_read函数,第二段对镜像文件test.img的读取采用了buff IO。
至此,已经能够解释为什么在设置了O_DIRECT标识的情况下,loop设备的吞吐量的比真实设备高那么多。loop设备在驱动层又将请求转发到了vfs层,进行对其关联镜像文件的第二段读取,在第二段读取的时候依然采用了buff IO。
读取loop设备的整体IO栈如下图所示。

后续工作
接下来分析一下,为什么第二段IO不能延续第一段IO的O_DIRECT标识。从loop_queue_work函数开始看loop驱动如何将第一次的请求转化为第二次的请求。
1 | loop_queue_work |
do_req_filebacked函数中对读写和不同的读写类型进行了处理,direct IO是通过非阻塞I/O来进行io的转发。可以看出,loop设备关联的镜像文件是单独进行读写方式设置的,与第一段IO读写的方式是不相干的。那么cmd->use_aio是在何时进行设置的?
1 | static int do_req_filebacked(struct loop_device *lo, struct request *rq) |
从man手册中loop下面可以看到,可以通过ioctl来设置backing file为direct IO模式。
查看loop驱动中的ioctl处理函数,loop_set_dio函数对该ioctl命令进行处理。
1 | //drivers/block/loop.c |
__loop_update_dio会对lo->use_dio进行判断和配置。
1 |
|
但是我们在驱动处理请求时判断diretIO是使用的cmd->use_aio,这个变量是何时和lo->use_dio关联起来的呢?
1 | static blk_status_t loop_queue_rq(struct blk_mq_hw_ctx *hctx, |
loop_queue_rq中对cmd->use_aio进行了赋值。最后,lo->use_dio的默认值在何时设置的?
loop_set_fd函数负责将loop设备和某个文件进行关联,在其中初始化了lo->use_dio为false。
1 | static int loop_set_fd(struct loop_device *lo, fmode_t mode, |
总结
至此,我们已经弄清了为什么loop设备在direct IO读写设置下,还是能够使用内核文件缓存。总结如下:
- loop设备关联的backing file ,其读写方式需要单独进行设置。
- loop设备关联文件的读写方式默认为buff IO。
- 系统通过ioctl系统调用,设置backing file的读写方式,对应的cmd为LOOP_SET_DIRECT_IO。

