1.摘要
存储设备的IO性能已从之前的数百IOPS加速到今天的数十万IOPS,并预计在未来几年内达到数千万IOPS。这一急剧演变主要归功于NAND-FLASH(闪存)器件及其数据并行设计的引入。
使用传统的机械存储设备(HDD),IO的延迟和吞吐量就受到这种旋转式存储设备的物理特性影响。通常HDD通过旋转磁盘盘片进行顺序访问速度较快,而通过移动磁头的随机访问却很慢,一代又一代的IO密集型算法和系统就是基于这两个基本特征而设计。固态硬盘(SSD)的出现正在改变这两个存储的性能特征,因为SSD的顺序IO和随机IO之间的延迟差异很小。固态硬盘的IO延迟为数十微秒,而硬盘为数十毫秒。SSD磁盘中的大量内部数据并行度实现了许多并发IO操作,从而使单个设备能够实现接近一百万次每秒IO(IOPS)的随机访问,而传统的磁性硬盘上仅有数百次IOPS。
2. IO瓶颈
现代存储设备的吞吐量现在通常受到其硬件(即,SATA/SAS或PCI-E)和软件接口的限制。硬件性能的如此快速飞跃暴露了以前未被注意到的软件级别的瓶颈,包括操作系统层和应用层。如今,在Linux环境下,单CPU内核可以支持80万IOPS左右的IO提交率。无论使用多少核来提交IO,操作系统块层都不能扩展到超过一百万IOPS。这对今天的固态硬盘来说可能够快了,但对明天的固态硬盘来说就不够快了。
由于目前操作系统中存在的性能瓶颈,一些应用程序和设备驱动程序已经选择绕过Linux块层来提高性能。此选择增加了驱动程序和硬件实现的复杂性。更具体地说,它在容易出错的驱动程序实现中增加了重复代码,并删除了通用操作系统存储层提供的通用功能,如IO调度和服务质量流量整形。
因此不放弃块层,又能提高存储性能,成为重要问题。
3. Linux块层传统实现
操作系统块层负责将IO请求从应用程序传送到存储设备。块层是一种粘合剂,一方面允许应用程序以统一的方式访问不同的存储设备,另一方面为存储设备和驱动程序提供来自所有应用程序的单一入口点。它是一个便捷库,可以对应用程序隐藏存储设备的复杂性和多样性,同时提供对应用程序有价值的公共服务。此外,数据块层实施IO公平性、IO错误处理、IO统计和IO调度,以提高性能并帮助保护最终用户免受其他应用程序或设备驱动程序的不良或恶意实施的影响。
应用程序通过内核系统调用提交IO,将其转换为称为块IO的数据结构。每个数据块IO包含IO地址、IO大小、IO形态(读或写)或IO类型(同步/异步)2等信息。然后,将其传输到libaio(用于异步IO)或直接传输到数据块层(用于将其提交到数据块层的同步IO)。一旦IO请求被提交,相应的数据块IO就被缓冲在临时区域中,该临时区域被实现为一个队列,表示为请求队列。
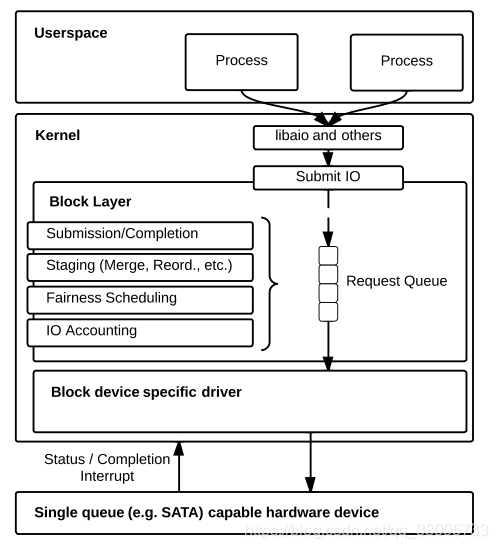
Linux块层支持可插拔IO调度器:NOOP、deadline和CFQ,它们都可以在此临时区域内操作IO。块层还提供了一种处理IO完成的机制:每次设备驱动程序中的IO完成时,该驱动程序都会调用堆栈来调用块层中的通用完成函数。然后,块层调用libaio库中的IO完成函数,或者从同步读或写系统调用返回,后者向应用程序提供IO完成信号。
在当前块层中,中转区由请求队列结构表示。每个块设备实例化一个这样的队列。所有块设备的访问都是统一的,应用程序不需要知道块层内的控制流模式。然而,这种针对每个设备的单一队列设计的结果是,块层不能支持跨设备的IO调度。
传统实现块层三个主要性能开销如下:
请求队列锁定。
块层通过IO请求队列实现同步访问独占资源。无论何时向请求队列插入数据块IO或从请求队列中删除数据块IO,都必须获取此锁。
scsi设备的请求处理函数scsi_request_fn如下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
* Function: scsi_request_fn()
*
* Purpose: Main strategy routine for SCSI.
*
* Arguments: q - Pointer to actual queue.
*
* Returns: Nothing
*
* Lock status: IO request lock assumed to be held when called.
*/
static void scsi_request_fn(struct request_queue *q)
__releases(q->queue_lock)
__acquires(q->queue_lock)
{
struct scsi_device *sdev = q->queuedata;
struct Scsi_Host *shost;
struct scsi_cmnd *cmd;
struct request *req;
...
}
进入函数时已经保证request_queue已经被lock。该函数名称后面多了releases,acquires两个宏定义,在大型项目中为了保证代码质量,会加入很多防御性编程代码,这样能够即时的把问题暴露出来。例如:
1 | // 函数本身是非线程安全的,需要在外边上锁保护 |
例子中dothing_unsafe中典型的防御性编程的代码就是通过assert调用,保证函数在调用时lock是持有状态的。但是assert本身调用会带来除函数逻辑以外的额外开销,因此会对性能造成影响。影响包括几个方面,一个是assert中的if判断有可能会对流水线并行造成不好的影响,这个影响可以通过gcc的__builtin_expect内置函数,提前告知编译器代码生成来规避。另外一个不好的影响是会增加可执行代码的大小,影响指令cache的局部性。
但其实更好的做法是,通过编译期的静态检查,将问题提前暴露出来,而不是留到运行期再发现问题。例如还是上述的例子,通过sparse的静态检查,可以这样写:
1 |
|
其中acquires(x) 和releases(x),acquire(x) 和release(x) 必须配对使用,都和锁有关。
每当通过IO提交操作请求队列时,必须获取该锁。
当I/O提交时,数据块层进行优化,如 plugging蓄洪(在将I/O发送到硬件之前先让I/O累积,以提高缓存效率)
IO重新排序和公平调度都必须获取请求队列锁,才能继续操作。
- 硬件中断
较高的IOPS数会导致成比例的高中断数。当今的大多数存储设备都是这样设计的,即一个内核(CPU0)负责处理所有硬件中断,并将它们作为软中断转发到其他内核。 因此,单个核可能花费相当多的时间来处理这些中断、上下文切换以及影响应用程序可能依赖的数据局部性的L1和L2高速缓存。然后,其他CPU核心也必须使用IPI(处理器间中断)来执行IO完成例程。因此,在许多情况下,仅完成一个IO就需要两次中断和上下文切换。
- 远程内存访问
当强制跨CPU核心(或NUMA体系结构中的跨套接字)进行远程内存访问时,请求队列锁争用会加剧。每当IO在与发出IO的内核不同的内核上完成时,就需要这样的远程内存访问。
在这种情况下,获取请求队列上的锁以从请求队列移除块IO引起对存储在上次获取该锁的核的高速缓存中的锁状态的远程存储器访问,然后在两个核上将高速缓存线标记为共享。更新时,副本将从远程缓存中显式失效。如果多个核正在主动发出IO并因此竞争此锁,则与此锁关联的缓存线将在这些核之间持续反弹。
4.多队列
通过使用具有不同功能的两级队列,将单个请求队列锁上的锁争用分布到多个队列,如图所示。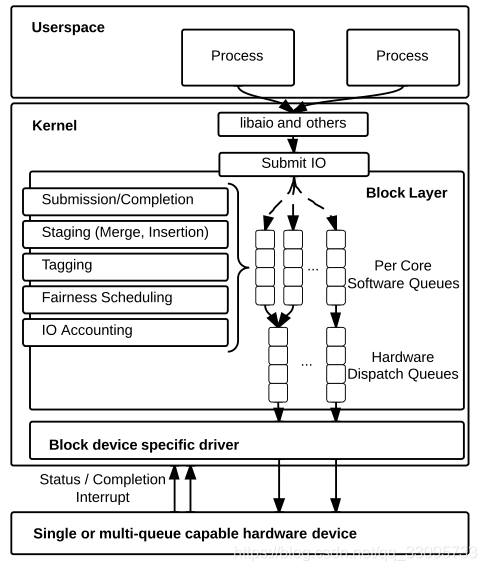
软件暂存队列。数据块IO请求现在维护在一个或多个请求队列的集合中,而不是将IO转移到单个软件队列中进行调度。可以配置这些分段队列,使得系统上的每个套接字或每个内核都有一个这样的队列。因此,在具有4个插槽和每个插槽6个核心的NUMA系统上,临时区域可能包含最少4个队列,最多24个队列。如果单个队列上的争用不是瓶颈,则请求队列的可变特性会减少锁的扩散。由于许多CPU体系结构为每个套接字(通常也是NUMA节点)提供了大型共享L3缓存,因此每个处理器套接字只有一个队列可以在不利于缓存的重复数据结构和锁争用之间进行很好的权衡。
硬件调度队列。IO进入分段队列后,我们引入了一个新的中间队列层,称为硬件分派队列。使用这些队列,计划分派的数据块IO不会直接发送到设备驱动程序,而是发送到硬件分派队列。硬件分派队列的数量通常与设备驱动程序支持的硬件上下文的数量相匹配。设备驱动程序可以选择支持消息信号中断标准MSI-X[25]所支持的1到2048个队列。因为在块层中不支持IO排序,所以任何软件队列都可以馈送任何硬件队列,而不需要维护全局排序。这允许硬件实现直接映射到NUMA节点或CPU的一个或多个队列,并提供从应用程序到硬件的快速IO路径,而无需访问任何其他节点上的远程内存。
5.多队列内核数据结构
单队列架构发起IO传输的核心函数是blk_queue_bio()。Multi queue多队列核心IO传输函数是blk_mq_make_request()。Multi queue多队列架构引入了struct blk_mq_tag_set、struct blk_mq_tag、struct blk_mq_hw_ctx、struct blk_mq_ctx等数据结构。最初阅读这些代码时,感觉比单队列复杂多了,很容易绕晕。
1 struct blk_mq_ctx代表每个CPU独有的软件队列;
2 struct blk_mq_hw_ctx代表硬件队列,块设备至少有一个;
3 struct blk_mq_tag每个硬件队列结构struct blk_mq_hw_ctx对应一个;
4 struct blk_mq_tag主要是管理struct request(下文简称req)的分配。struct request大家应该都比较熟悉了,单队列时代就存在,IO传输的最后都要把bio转换成request;
5 struct blk_mq_tag_set包含了块设备的硬件配置信息,比如支持的硬件队列数nr_hw_queues、队列深度queue_depth等,在块设备驱动初始化时多处使用blk_mq_tag_set初始化其他成员;
每个CPU对应唯一的软件队列blk_mq_ctx,blk_mq_ctx对应唯一的硬件队列blk_mq_hw_ctx,blk_mq_hw_ctx对应唯一的blk_mq_tag,三者的关系在后续代码分析中多次出现。
以nvme驱动程序初始化代码为例,分析多请求队列的源码,从函数nvme_dev_add开始。
nvme_dev_add()函数中设置blk_mq_tag_set结构的关键成员;分配设置每个硬件队列独有blk_mq_tag结构;分配并设置struct blk_mq_tag_set *set的set->mq_map[]数组,该数组下标是CPU的编号,数组成员是硬件队列的编号,这样就完成了CPU编号与硬件队列编号的映射。
1 | /* |
1 |
|
如注释,关键是调用函数blk_mq_alloc_rq_maps()分配每个硬件队列独有的blk_mq_tags结构,并初始化其成员,该函数源码如下:
1 |
|
1 |
|
1 |
|
blk_mq_alloc_rq_map()函数只分配struct blk_mq_tags *tags的tags->static_rqs[]这个req指针数组,实际分配req是在blk_mq_alloc_rqs()函数,源码如下。
1 |
|
接着是初始化的后半部分,在 blk_mq_init_queue()中完成。该函数主要分配块设备的运行队列request_queue,接着分配每个CPU专属的软件队列并初始化,分配硬件队列并初始化,然后建立软件队列和硬件队列的映射。
1 | struct request_queue *blk_mq_init_queue(struct blk_mq_tag_set *set) |
blk_mq_init_queue函数整体来说,是创建request_queue运行队列并初始化其成员,分配每个CPU专属的软件队列,分配硬件队列,对二者做初始化,并建立软件队列和硬件队列联系。
1 |
|
简单总结来说,blk_mq_init_allocated_queue函数负责分配每个CPU专属的软件队列,分配硬件队列,对二者做初始化,分配,并建立软件队列和硬件队列联系。该函数中调用的blk_mq_realloc_hw_ctxs()、blk_mq_map_swqueue()是两个重点函数,下文列出了源码注释。
1 |
|
blk_mq_realloc_hw_ctxs()函数很重要,分配每一个硬件队列具体的数据结构blk_mq_hw_ctx。然后主要为该结构的tags和sched_tags成员,分配赋值每个硬件队列必须的blk_mq_tags。之后进行IO传输前,要从hctx->tags-> static_rqs[]或者hctx->sched_tags-> static_rqs[]分配一个req。该函数中调用的blk_mq_init_hctx()主要是初始化blk_mq_hw_ctx硬件队列成员,分配调度算法hctx->sched_tags需要的blk_mq_tags。
1 |
|
blk_mq_map_swqueue()函数主要作用是,根据CPU编号取出硬件队列结构struct blk_mq_ctx *ctx和软件队列结构struct blk_mq_ctx *ctx,然后把软件队列结构赋值给硬件队列结构,即hctx->ctxs[hctx->nr_ctx++] = ctx,相当于完成硬件队列与软件队列的映射。
1 |
|
每个CPU对应唯一的软件队列blk_mq_ctx,blk_mq_ctx对应唯一的硬件队列blk_mq_hw_ctx,blk_mq_hw_ctx对应唯一的blk_mq_tags。我们在进行发起bio请求后,需要从blk_mq_tags结构的相关成员分配一个tag(其实是一个数字),再根据tag分配一个req,最后才能进行IO派发,磁盘数据传输。
6. request的分配与发送
在多队列io中,blk_mq_make_request函数负责request的处理,该函数代码注释如下:
1 |
|
每个进程都在task_struct结构体中,维护一个blk_plug *plug;变量,blk_plug定义如下:
1 |
|
list:用于缓存请求的队列
mq_list:缓存硬件队列数是1的进程请求,延缓向驱动发送请求
cb_list:回调函数的链表
blk_mq_make_request()函数包含的核心函数较多,基本流程是,
先尝试把bio合并到软件队列或plug队列或调度算法队列。
如果无法合并,则执行blk_mq_sched_get_request()分配tag和req。这里出现”了分配tag”。这是与单队列时代的一个明显区别。
这里先简单介绍一下,多队列IO传输,将bio转换成req(就是sturct request),大体过程是这样的:先根据当前进程所在CPU,找到CPU对应的软件队列blk_mq_ctx(获取过程见blk_mq_get_ctx函数,每个CPU都有一个唯一的软件队列),再根据软件队列blk_mq_ctx得到其映射的硬件队列blk_mq_hw_ctx(获取过程见blk_mq_map_queue函数,每个软件队列对应唯一的硬件队列)。硬件队列blk_mq_hw_ctx结构中有两个关键成员struct blk_mq_tags *tags(针对无调度算法)和struct blk_mq_tags *sched_tags(针对有调度算法)。
有了硬件队列结构blk_mq_hw_ctx,得到其成员struct blk_mq_tags *tags指向的blk_mq_tags结构。blk_mq_tags结构又有几个关键成员:
struct sbitmap_queue bitmap_tags
struct sbitmap_queue breserved_tags
struct request **static_rqs
unsigned int nr_reserved_tags
static_rqs这个指针数组保存了nr_tags个req指针,实际的req结构在前文的__blk_mq_alloc_rq_map->blk_mq_alloc_rqs分配。
struct sbitmap_queue bitmap_tags和struct sbitmap_queue breserved_tags分析下来有点像ext4 文件系统的inode bitmap,一个bit位表示一个req的使用情况,1为已经分配,0为未分配。
struct sbitmap_queue breserved_tags管理static_rqs[0~ (nr_reserved_tags-1]]这nr_reserved_tags个req,struct sbitmap_queue bitmap_tags管理static_rqs[ nr_reserved_tags ~ nr_tags]这nr_tags- nr_reserved_tags个req。
分配tag和req的一般情况:从struct sbitmap_queue bitmap_tags分析出哪个req是空闲的,返回一个数字,这个数字就是tag,表示了static_rqs[] 中哪个位置的req是空闲的。实际情况tag+ nr_reserved_tags才能表示实际空闲的req在static_rqs[]中的下标。每一个req在派发给驱动时,必须得先分配一个tag。
7.利用bcc工具采集每个cpu核心下对应硬件队列可以存储的请求数
blk_mq_map_queue函数的功能是获取软件队列对应的硬件队列,通过硬件队列结构体blk_mq_hw_ctx中的变量tags->nr_tags和nr_reserved_tags取和获取当前cpu下硬件队列存储的请求数。但是由于内核5.0以上,相关结构体已经改变,没有运行成功,需要在内核4.x上安装bcc运行。
1 |
|
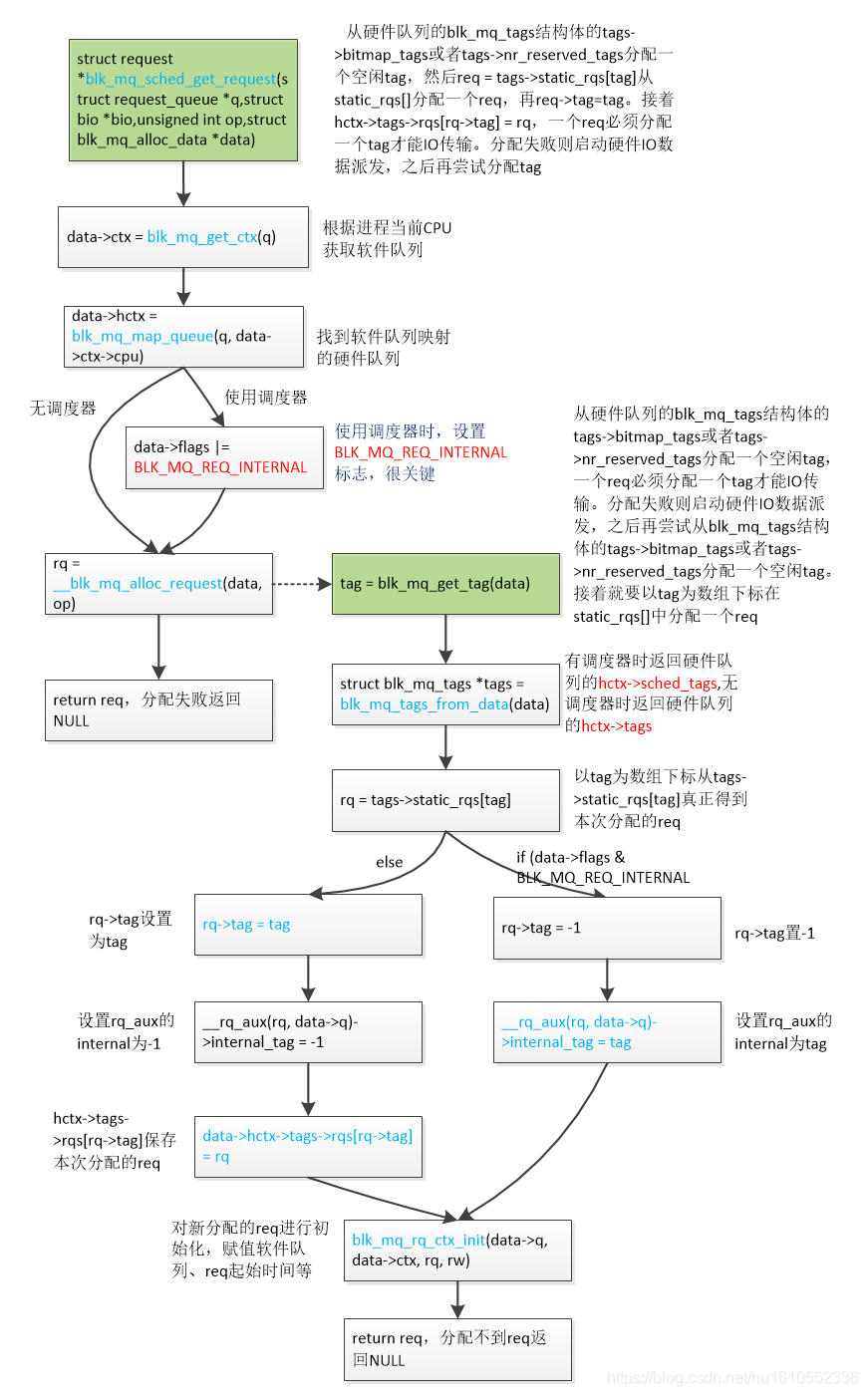
8. blk_mq_sched_get_request()分配tag和req
该函数主要作用是:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,然后req = tags->static_rqs[tag]从static_rqs[]分配一个req,再req->tag=tag。接着hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag。如果留意的话,这就是上一节介绍的tag和req的分配过程,更详细的步骤看下边的__blk_mq_alloc_request函数。流程如下。
1 |
|
__blk_mq_alloc_request函数的大体过程是:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag,然后req = tags->static_rqs[tag]从static_rqs[]分配一个req,再req->tag=tag。接着hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag。函数核心是执行blk_mq_get_tag()分配tag。
1 |
|
9. request direct直接派发
blk_mq_try_issue_directly() 将req direct直接派发给磁盘设备驱动。
1 |
|
核心是执行 __blk_mq_try_issue_directly()函数。
1 |
|
__blk_mq_try_issue_directly函数的详细流程:从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag,循环,直到分配req成功。然后调用磁盘驱动queue_rq接口函数向驱动派发req,启动磁盘数据传输。如果遇到磁盘驱动硬件忙,则释放req的tag,设置硬件队列忙。
其实核心就两点:1为req分配tag;2把req派发给磁盘驱动,启动磁盘数据传输。有人可能会问,不是在blk_mq_make_request->blk_mq_sched_get_request 中已经为req分配过tag了,为什么这里还要再分配?关于这一点,我的分析是,如果req已经分配过tag了,执行blk_mq_get_driver_tag函数(下一节讲)会直接返回。但是会存在这种情况,req在派发给磁盘驱动时,磁盘驱动硬件繁忙,派发失败,则会把req加入硬件队列hctx->dispatch链表,然后把req的tag释放掉,则req->tag=-1,等空闲时派发该req。好的,空闲时间来了,再次派发该req,此时就需要执行blk_mq_get_driver_tag为req重新分配一个tag。一个req在派发给驱动时,必须分配一个tag!
__blk_mq_issue_directly是直接将req派发给驱动的核心函数。
1 |
|
基本是调用磁盘驱动层的函数,将req有关的磁盘传输信息发送给驱动,然后会进行磁盘数据传输。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag。
blk_mq_get_driver_tag() 在req派发给驱动前分配tag。
1 | bool blk_mq_get_driver_tag(struct request *rq, struct blk_mq_hw_ctx **hctx, |
从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,然后hctx->tags->rqs[rq->tag] = rq,一个req必须分配一个tag才能IO传输。分配失败则启动硬件IO数据派发,之后再尝试分配tag,循环。
可以发现,该函数本质还是调用前文介绍过的blk_mq_get_tag()去硬件队列的blk_mq_tags结为req分配一个tag。该函数只是分配tag,没有分配req。blk_mq_get_driver_tag()存在的意义是:req派发给磁盘驱动时,遇到磁盘硬件队列繁忙,无法派送,则释放掉tag,req加入硬件hctx->dispatch链表异步派发。等再次派发时,就会执行blk_mq_get_driver_tag()为req分配一个tag。
10. 软件队列ctx->rq_list、硬件hctx->dispatch、IO算调度法队列链表上的req派发
blk_mq_try_issue_directly()类的req direct 派发是针对单个req的,blk_mq_run_hw_queue()是派发类软件队列ctx->rq_list、硬件hctx->dispatch链表、IO调度算法队列上的req的,这是二者最大的区别。
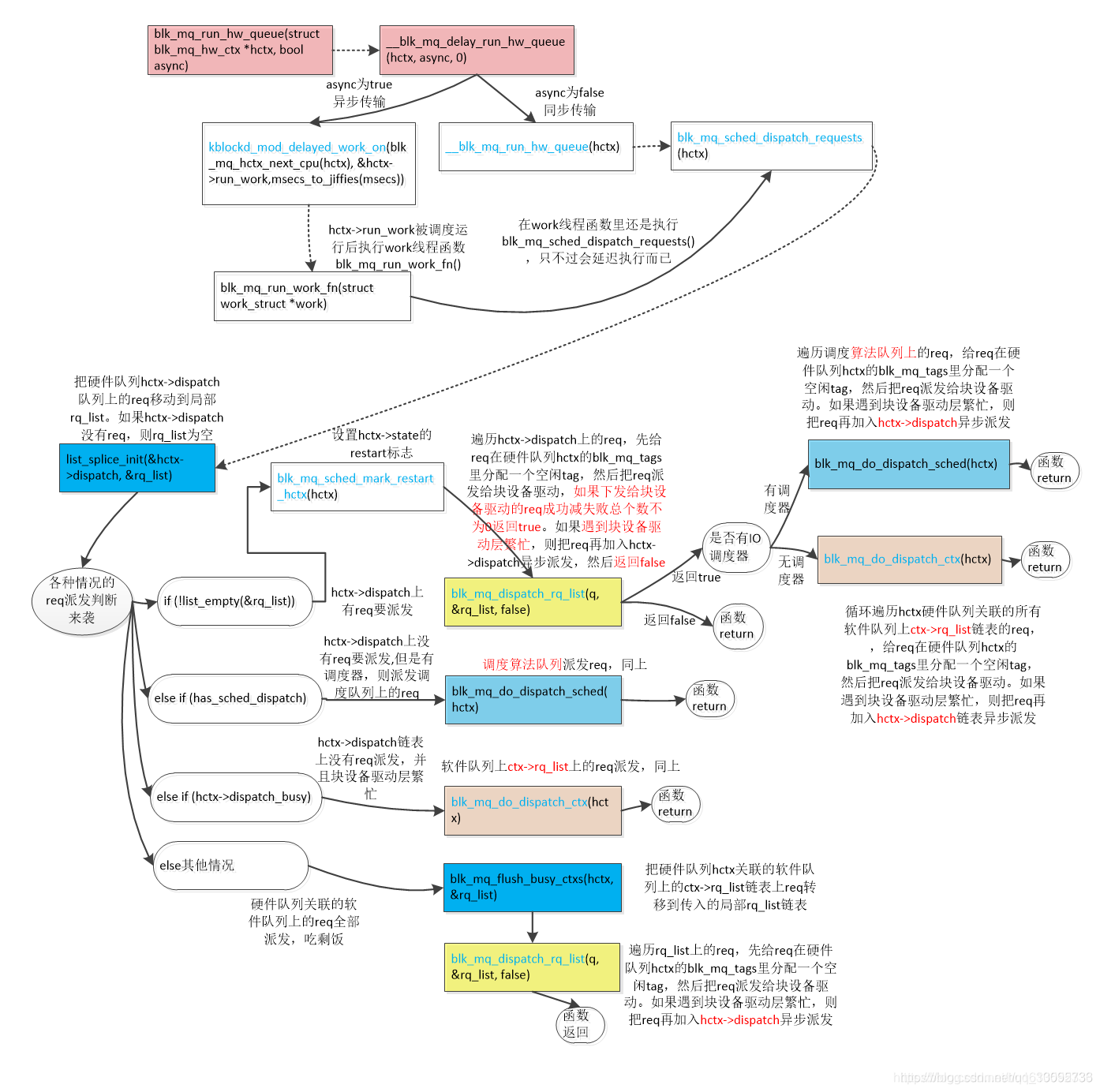
启动硬件队列上的req派发到块设备驱动。
1 | bool blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async)//async为true表示异步传输,false表示同步 |
1 | static void __blk_mq_delay_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async,//async为true则异步,false则同步传输unsigned long msecs)// msecs决定派发延时 |
1 |
|
核心是调用blk_mq_sched_dispatch_requests ()函数。blk_mq_sched_dispatch_requests()函数派发各种队列的req。
1 | void blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx) |
总结下来,主要是3种情况
1 执行blk_mq_dispatch_rq_list()派发硬件队列hctx->dispatch链表上的req
2执行blk_mq_do_dispatch_sched()派发调度器队列上的req。
3执行blk_mq_do_dispatch_ctx ()函数派发软件队列ctx->rq_list链表上的req。
blk_mq_do_dispatch_sched() 和blk_mq_flush_busy_ctxs()最后也是指定的blk_mq_dispatch_rq_list()函数进行实际的派发。
10.1 blk_mq_do_dispatch_sched()派发调度器队列上的req
这里以deadline调度算法为例。执行deadline算法派发函数,循环从fifo或者红黑树队列选择待派发给传输的req,然后给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,接着把req派发给块设备驱动。如果磁盘驱动硬件繁忙,则把req转移到hctx->dispatch队列,然后启动req异步传输。硬件队列繁忙或者算法队列没有req了则跳出循环返回。
1 |
|
10.2 blk_mq_do_dispatch_ctx ()派发软件队列ctx->rq_list链表上的req
循环遍历hctx硬件队列关联的所有软件队列上ctx->rq_list链表的req,给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,然后把req派发给块设备驱动。如果遇到块设备驱动层繁忙,则把req再加入hctx->dispatch链表异步派发。
1 |
|
10.3 blk_mq_dispatch_rq_list()实际完成对各个队列上的req的派发
list来自hctx->dispatch硬件派发队列、软件队列rq_list链表上、调度算法队列等req。遍历list上的req,先给req在硬件队列hctx的blk_mq_tags里分配一个空闲tag,然后调用磁盘驱动queue_rq函数派发req。任一个req要启动硬件传输前,都要从blk_mq_tags结构里得到一个空闲的tag。如果遇到磁盘驱动硬件繁忙,则要把这个派发失败的req再添加list链表,再把list链表上的所有req转移到hctx->dispatch队列,之后启动异步派发时再从hctx->dispatch链表上取出这些req派发。下发给驱动的req成功减失败总个数不为0返回true,其他返回false。
可以发现一个规律,最终肯定调用磁盘驱动的queue_rq函数才能把req派送给磁盘驱动,然后才能进行磁盘数据传输。但是该函数有三个返回值,一是BLK_MQ_RQ_QUEUE_OK,表示派送req成功;BLK_MQ_RQ_QUEUE_DEV_BUSY或者BLK_MQ_RQ_QUEUE_BUSY,表示磁盘驱动硬件繁忙,则无法派送req,需要把req再放入hctx->dispatch链表,之后进行异步派发。异步派发最后还是执行blk_mq_dispatch_rq_list()函数。
1 | bool blk_mq_dispatch_rq_list(struct request_queue *q, struct list_head *list, |
11. request plug形式的派发
blk_flush_plug_list()派发plug->mq_list链表上的req。
1 |
|
核心是执行blk_mq_flush_plug_list函数。
函数核心流程:每次循环,取出plug->mq_list上的req,添加到ctx_list局部链表。如果每两次取出的req都属于一个软件队列,只是把这些req添加到局部ctx_list链表,该函数最后执行blk_mq_sched_insert_requests把ctx_list链表上的req进行派发。如果前后两次取出的req不属于一个软件队列,则立即执行blk_mq_sched_insert_requests()将ctx_list链表已经保存的req进行派发,然后把本次循环取出的req继续添加到ctx_list局部链表。
简单来说,blk_mq_sched_insert_requests()只会派发同一个软件队列上的req。该函数req的派发,如果有调度器,则把req先插入到IO算法队列;如果无调度器,会尝试执行blk_mq_try_issue_list_directly直接将req派发给磁盘设备驱动。最后再执行blk_mq_run_hw_queue()把剩余的因各种原因未派发的req进行同步或异步派发。
1 | void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule) |
11.1 blk_mq_sched_insert_requests真正派发plug->mq_list链表上的req
1 |
|
如果有IO调度算法,则把list(来自plug->mq_list)链表上的req插入elv的hash队列,mq-deadline算法的还要插入红黑树和fifo队列。如果没有使用IO调度算法,则执行blk_mq_try_issue_list_directly函数,在该函数中:取出list链表的上的req,从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于req->tag,然后调用磁盘驱动queue_rq接口函数把req派发给驱动。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag。然后把这个失败派送的req插入hctx->dispatch链表,此时如果list链表空则执行blk_mq_run_hw_queue同步派发req(这个过程见blk_mq_request_bypass_insert),接着就return返回了。
因为此时磁盘驱动硬件忙,不能再继续把list剩余的req再强制进行派发了,则执行blk_mq_insert_requests函数把这些剩余未派发的req插入到软件队列ctx->rq_list链表上,然后执行blk_mq_run_hw_queue再进行req同步或异步派发。下文重点介绍函数blk_mq_try_issue_list_directly。
1 |
|
依次遍历list(来自plug->mq_list)链表上的req,执行blk_mq_request_issue_directly()派发该req。在该函数中,从硬件队列的blk_mq_tags结构体的tags->bitmap_tags或者tags->nr_reserved_tags分配一个空闲tag赋于rq->tag,调用磁盘驱动queue_rq接口函数把req派发给驱动。如果遇到磁盘驱动硬件忙,则设置硬件队列忙,还释放req的tag,然后把这个派送失败的req插入hctx->dispatch链表,此时如果list链表空则执行blk_mq_run_hw_queue同步派发req,之后就从blk_mq_request_issue_directly函数返回。如果遇到req传输完成则执行blk_mq_end_request()统计IO使用率等数据并唤醒进程。
blk_mq_request_issue_directly函数呢,调用__blk_mq_try_issue_directly()执行具体的req派发工作。
1 |
|
进程plug->mq_list链表上的req派送,一个个是先执行blk_mq_try_issue_list_directly直接将req派送给磁盘驱动进行数据传输。如果遇到磁盘驱动硬件繁忙,还是要把req加入hctx->dispatch链表。接着还要把plug->mq_list链表上剩余未派发的req加入软件队列ctx->rq_list链表上。最后执行blk_mq_run_hw_queue()再把hctx->dispatch链表和ctx->rq_list链表上的req进行同步或者异步派发。
12. 总结
软件队列ctx->rq_list链表、硬件队列hctx->dispatch链表、IO调度算法队列的相关链表、req plug模式的plug->mq_list,blk_mq_try_issue_list_directly、__blk_mq_try_issue_directly direct 派发模式。
硬件队列hctx->dispatch链表,正常情况下它用不到。只有在req派发时,发现磁盘驱动硬件繁忙,暂时没时间处理该req,又不能不管,只能先把req添加到硬件队列hctx->dispatch链表。接着执行blk_mq_run_hw_queue类的函数,该函数会在磁盘驱动硬件空闲时,从hctx->dispatch链表取出刚才没来得及派发的req,再次尝试派发给磁盘设备驱动。
软件队列ctx->rq_list链表,向该链表插入req的情况是:发起bio请求过程的blk_mq_make_request()->blk_mq_queue_io();执行blk_mq_sched_insert_requests派发req时:情况1,如果硬件队列繁忙或者使用了调度器或者异步派发,不能执行blk_mq_try_issue_list_directly()直接将req派发给设备驱动的情况下,那就执行blk_mq_insert_requests()将派发req的临时list链表上的req插入到软件队列ctx->rq_list链表;情况2,硬件队列空闲且没有使用调度器且同步派发,则执行blk_mq_try_issue_list_directly()将临时list链表上的req派发给磁盘设备驱动。但派发过程遇到了磁盘驱动硬件繁忙,只能被迫返回,接着还是执行blk_mq_insert_requests()将list链表上剩下未派发的req插入到ctx->rq_list链表。之后执行blk_mq_run_hw_queue类函数,在磁盘驱动硬件空闲时,从软件队列ctx->rq_list链表取req,再次尝试派发给设备驱动。
IO调度算法队列的相关链表,这是执行设置了IO调度算法的情况下,肯定要先把派发的req插入的IO算法队列相关链表进行处理。它的派发见blk_mq_make_request()和blk_mq_sched_insert_requests()中调用的blk_mq_sched_insert_request函数。
req plug模式的plug->mq_list链表。就是当前进程集聚了很多bio在plug->mq_list,然后一下次全部派发给磁盘设备驱动。它的发起函数是blk_flush_plug_list。基本原理是,先取出plug->mq_list链表上的req,如果设置了IO调度器,则把req插入到IO算法队列。否则,则先执行blk_mq_try_issue_list_directly()将这些req直接派发给磁盘设备驱动。如果无法直接派发给磁盘设备驱动,就先把req添加到软件队列ctx->rq_list链表,等稍后执行blk_mq_run_hw_queue类函数,再次尝试派发这些req。
原文链接:https://blog.csdn.net/hu1610552336/article/details/111464548


