1.前言
PageCache又称页高速缓存,页高速缓存是由内存中的物理页面组成,对应的是磁盘上的物理块,可以动态扩大缩小。Linux支持的文件大小可以达到TB级别,访问较大文件时高速缓存中会存储属于该文件大量的页,因此采用struct address_space对页高速缓存进行管理,同时设计了基树结构来加速对缓存中页的查找。
早期的Linux内核版本中,同时存在PageCache和BufferCache,前者用于缓存对文件操作的内容,后者用于缓存直接对块设备操作的内容。page cache按照文件的逻辑页进行缓冲,buffer cache按照文件的物理块进行缓冲。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。由于这两种缓存处于半独立的状态,缺乏集成导致整体性能下降和缺乏灵活性。在内核版本2.4之后,对Page Cache、Buffer Cache的实现进行了融合,融合后的Buffer Cache不再以独立的形式存在,Buffer Cache的内容,直接存在于Page Cache中,同时,保留了对Buffer Cache的描述符单元:buffer_head。
2. address_space结构体
address_space负责管理页面高速缓存,索引节点(inode)的i_mapping字段总是指向索引节点的数据页所有者的address_space对象。
address_space对象的host字段指向其所有者的索引节点对象。
1 |
|
内核可以通过基树索引结构快速判断所需要的页是否在页高速缓存中。当查找所需要的页时,内核把页索引转换为基树的路径,并快速找到页描述符所在位置。如果找到,内核可以从基树获得页描述符,并且确定所找到的页是否是脏页,以及其数据是否正在使用。一个address_space代表一个基树,用page_tree来关联树根节点。
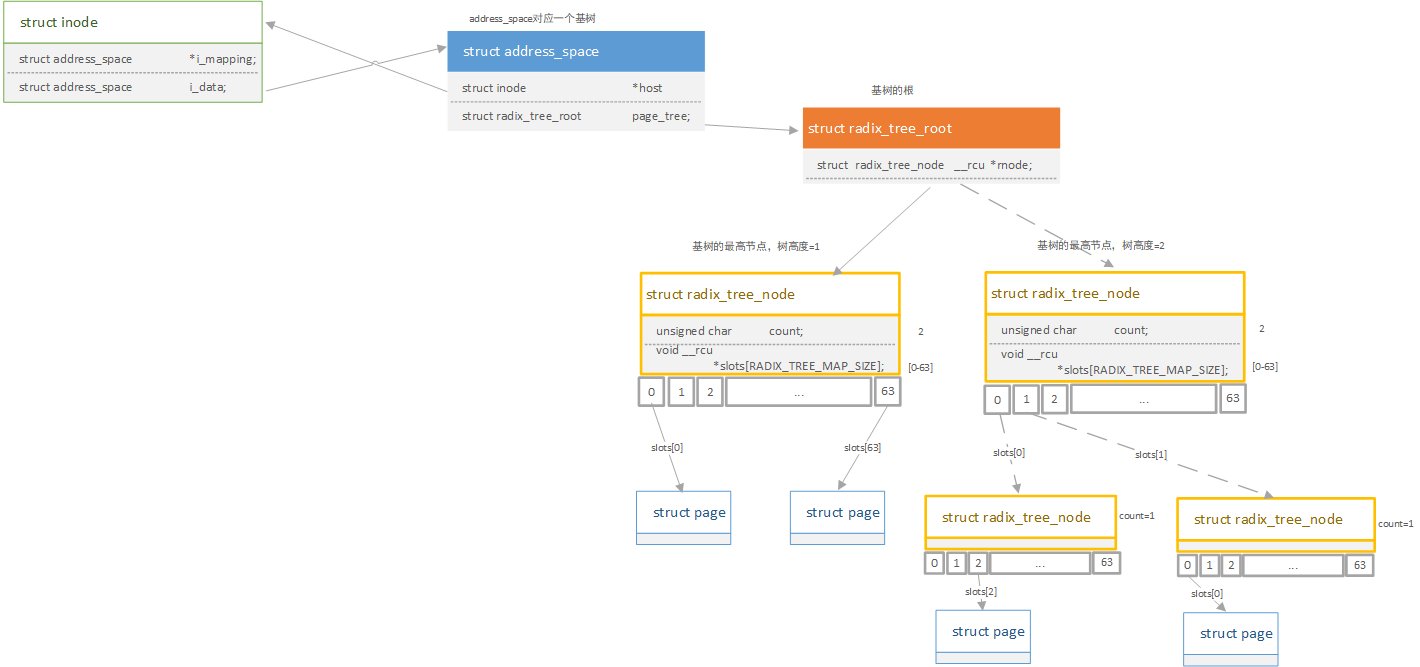
基树的叶子节点为page结构体,中间节点为代表基树节点的radix_tree_node。基树每个节点可以有多到64个指针指向其他节点或页描述符。每个节点由radix_tree_node数据结构表示, slots是包含64个指针的数组,count是记录节点中非空指针数量的计数器,tags是二维的标志数组。树根由radix_tree_root数据结构表示,gfp_mask指定新节点请求内存时所用的标志,rnode指向与树中第一层节点相应的数据结构radix_tree_node。
若基树深度为1,则只能表示从0至63的索引,则页索引(上文提高的index字段)的低6位进行解析,从而对应成radix_tree_node结构中的slot下标,找到对应的页;若基树深度为2,则页索引的低12位分成05,611两个字段进行解析。分别找到第一层slot字段和第二层slot字段的值。
3. bufferCache
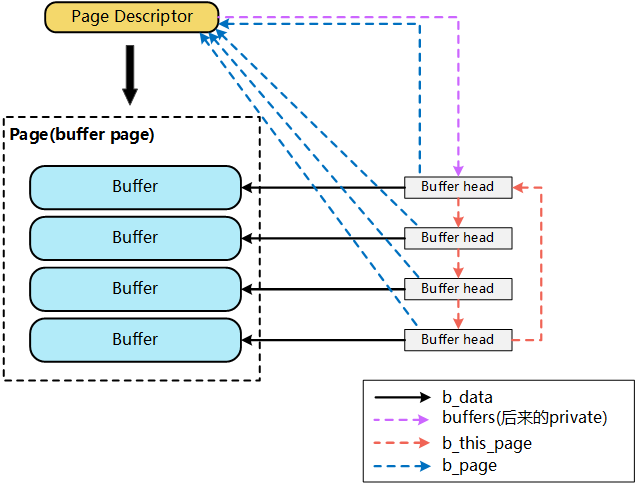
bufferCache存放在叫做“缓冲区页”的专门页中,并且使用称为bufferHead的缓冲区头部来描述一个页中的数据块在磁盘中的位置。
1 | struct buffer_head { |
融合后的buffer和cache如下图所示。
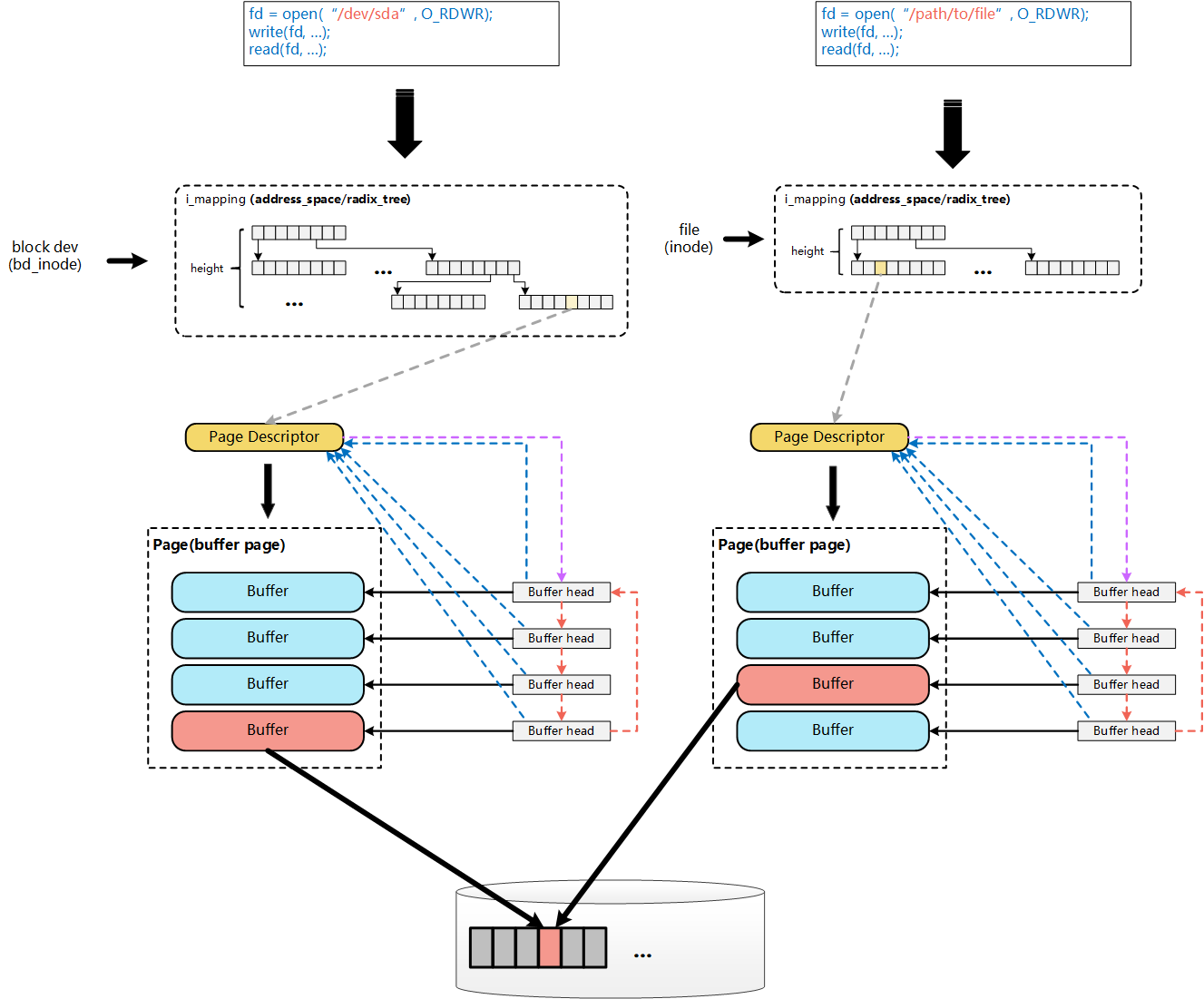
一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构(该inode结构也会在对应的file结构体中引用),其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。
因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。address_space_operations 就是用来操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。
file结构体和inode结构体中都有一个address_space结构体指针,实际上,file->f_mapping是从对应inode->i_mapping而来,inode->i_mapping->a_ops是由对应的文件系统类型在生成这个inode时赋予的。
address_space_operations 包含以下方法。
writepage 写操作,从页写到所有者的磁盘映像
readpage 读操作,从所有者的磁盘映像读到页
sync_page 如果对所有者页进行的操作已准备好,则立刻开始I/O数据的传输
writepages 把指定数量的所有者脏页写回磁盘。
set_page_dirty 把所有者的页设置为脏页
readpages 从磁盘中读所有者页的链表
prepare_write 为写操作做准备(由磁盘文件系统使用)
commit_write 完成写操作(由磁盘文件系统使用)
bmap 从文件块索引中获取逻辑块号
invalidatepage 是所有者的页无效(截断文件时使用)
releasepage 由日志文件系统使用以准备释放页
direct_IO 所有者页的直接I/O传输 (绕过了页高速缓存 page cache)
操作普通文件和操作设备文件过程如下图所示。
4. Cache 预读
文件Cache可以看做是内存管理系统与文件系统之间的联系纽带。因此,文件Cache管理是操作系统的一个重要组成部分,它的性能直接影响着文件系统和内存管理系统的性能。
大多数磁盘I/O读写都是顺序的,且普通文件在磁盘上的存储都是占用连续的扇区。这样读写文件时,就可以减少磁头的移动次数,提升读写性能。当程序读一个文件时,它通常从第一字节到最后一个字节顺序访问。因此,同一个文件中磁盘上多个相邻的扇区通常会被读进程都访问。
预读(read ahead)就是在数据真正被访问之前,从普通文件或块设备文件中读取多个连续的文件页面到内存中。多数情况下,内核的预读机制可以明显提高磁盘性能,因为减少了磁盘控制器处理的命令数,每个命令读取多个相邻扇区。此外,预读机制还提高了系统响应时间。
当然,在进程大多数的访问是随机读时,预读是对系统有害的,因为它浪费了内核Cache 空间。当内核确定最近常用的I/O访问不是顺序的时,就会减少或关闭预读。
预读(read-ahead)算法预测即将访问的页面,并提前把它们批量的读入缓存。
它的主要功能和任务包括:
- 批量:把小I/O聚集为大I/O,以改善磁盘的利用率,提升系统的吞吐量。
提前:对应用程序隐藏磁盘的I/O延迟,以加快程序运行。
预测:这是预读算法的核心任务。
前两个功能的达成都有赖于准确的预测能力。当前包括Linux、FreeBSD和Solaris等主流操作系统都遵循了一个简单有效的原则: 把读模式分为随机读和顺序读两大类,并只对顺序读进行预读。这一原则相对保守,但是可以保证很高的预读命中率,同时有效率/覆盖率也很好。因为顺序读是最简单而普遍的,而随机读在内核来说也确实是难以预测的。
以dd程序读一个裸设备为例,每次读1K数据,连续读16次:
szp@szp-pc:~$ sudo dd if=/dev/sdb of=/dev/zero bs=1K count=16 [sudo] szp 的密码: 记录了16+0 的读入 记录了16+0 的写出 16384 bytes (16 kB, 16 KiB) copied, 0.000382103 s, 42.9 MB/s
blktrace工具记录情况如下:
szp@szp-pc:~$ sudo blktrace -d /dev/sdb -o - | blkparse -i - 8,16 1 1 0.000000000 2453 Q RA 0 + 32 [dd] 8,16 1 2 0.000006462 2453 G RA 0 + 32 [dd] 8,16 1 3 0.000007073 2453 P N [dd] 8,16 1 4 0.000008215 2453 U N [dd] 1 8,16 1 5 0.000008967 2453 I RA 0 + 32 [dd] 8,16 1 6 0.000013205 2453 D RA 0 + 32 [dd] 8,16 1 7 0.000094959 2453 C RA 0 + 32 [0] 8,16 1 8 0.000124926 2453 Q RA 32 + 64 [dd] 8,16 1 9 0.000125988 2453 G RA 32 + 64 [dd] 8,16 1 10 0.000126169 2453 P N [dd] 8,16 1 11 0.000126399 2453 U N [dd] 1 8,16 1 12 0.000126639 2453 I RA 32 + 64 [dd] 8,16 1 13 0.000127681 2453 D RA 32 + 64 [dd] 8,16 1 14 0.000189909 2453 C RA 32 + 64 [0]
- 第一个字段:8,16 这个字段是设备号 major device ID和minor device ID。
- 第二个字段:1 表示CPU
- 第三个字段:14 序列号
- 第四个字段:0.000189909 Time Stamp是时间偏移
- 第五个字段:PID 本次IO对应的进程ID
- 第六个字段:Event,这个字段非常重要,反映了IO进行到了哪一步
- 第七个字段:R表示 Read, W是Write,D表示block,B表示Barrier Operation
- 第八个字段:223490+56,表示的是起始block number 和 number of blocks,即我们常说的Offset 和 Size
- 第九个字段: 进程名
简单介绍blktrace工具,blktrace 结合btt可以统计一个IO是在调度队列停留的时间长,还是在硬件上消耗的时间长,利用这个工具可以协助分析和优化问题,可以更好的追踪IO的过程。
其中第六个字段非常有用:每一个字母都代表了IO请求所经历的某个阶段。
Q – 即将生成IO请求(bio)
|
G – IO请求(request)生成
|
I – IO请求进入IO Scheduler队列
|
D – IO请求进入driver
|
C – IO请求执行完毕
上面的输出可以简单解析为:
Q :dd程序派发的第一个bio进入通用块层,该bio大小为32个扇区,包括了dd总共需要读取的16k数据。
G :获得一个request,用第一个bio初始化。
[P-C] : 第一个bio在通用块层后续的处理。
Q : dd程序派发的第二个bio进入通用块层,该bio大小为64个扇区,该bio为预读触发的请求。
G : 同样获得一个request,用第二个bio初始化。读操作同步进行,不会与前一个请求产生合并。
[P-C] : 第二个在通用块层的处理。
读操作是同步的,所以触发读请求的是dd进程本身。dd进程发起了16次读操作,总共读取16K数据,但是预读机制只向底层发送了两次读请求,分别为0+32(16K), 32+64(32K),总共预读了16 + 32 = 48K数据,并保存到cache中,多预读的数据可以为后续的读操作服务。
内核判断两次读访问是顺序的标准是:
请求的第一个页面与上次访问的最后一个页面是相邻的。
访问一个给定的文件,预读算法使用两个页面集:当前窗口(current window)和前进窗口(ahead window)。
当前窗口(current window)包括了进程已请求的页面或内核提前读且在页面cache中的页面。(当前窗口中的页面未必是最新的,因为可能仍有I/O数据传输正在进行。)
前进窗口(ahead window)包含的页面是紧邻当前窗口(current window)中内核提前读的页面。前进窗口中的页面没有被进程请求,但内核假设进程迟早会访问这些页面。当内核判断出一个顺序访问和初始页面属于当前窗口时,就检查前进窗口是否已经建立起来。若未建立,内核建立一个新的前进窗口,并且为对应的文件页面触发读操作。
在理想状况下,进程正在访问的页面都在当前窗口中,而前进窗口中的文件页面正在传输。当进程访问的页面在前进窗口中时,前进窗口变为当前窗口。
5.预读数据结构与函数
5.1 file_ra_state数据结构
预读算法使用的主要数据结构是file_ra_state,每个文件对象都有一个f_ra域。其定义在文件include/linux/fs.h中。
1 |
|
ra_pages表示当前窗口的最大页面数,也就是针对该文件的最大预读页面数;其初始值由该文件所在块设备上的backing_dev_info描述符中。进程可以通过系统调用 posix_fadvise()来改变已打开文件的ra_pages值来调优预读算法。
5.2 generic_file_buffered_read
读文件函数路径如下:
1 | read() |
内核处理用户进程的读数据请求时,使用最多的是调用page_cache_sync_readahead()和page_cache_async_readahead()函数来执行预读。
1 |
|
do_generic_file_read()首先调用find_get_page()检查页是否已经包含在页缓存中。如果没有则调用page_cache_sync_readahead()发出一个同步预读请求。预读机制很大程度上能够保证数据已经进入缓存,因此再次调用find_get_page()查找该页。这次仍然有一定失败的概率,那么就跳转到标号no_cached_page处直接进行读取操作。检测页标志是否设置了PG_readahead,如果设置了该标志就调用page_cache_async_readahead()启动一个异步预读操作,这与前面的同步预读操作不同,这里并不等待预读操作的结束。虽然页在缓存中了,但是其数据不一定是最新的,这里通过PageUptodate(page)来检查。如果数据不是最新的,则调用函数mapping->a_ops->readpage()进行再次数据读取。
5.3 page_cache_sync_readahead()
page_cache_sync_readahead()函数就是同步预读一些页面到内存中。
page_cache_sync_readahead()它重新装满当前窗口和前进窗口,并根据预读命中率来更新窗口大小。函数有5个参数:
mapping:文件拥有者的addresss_space对象
ra:包含此页面的文件file_ra_state描述符
filp:文件对象
offset:页面在文件内的偏量
req_size:完成当前读操作需要的页面数
1 |
|
当文件模式设置FMODE_RANDOM时,表示文件预期为随机访问。这种情形比较少见,这里不关注。函数变成对ondemand_readahead()封装。
page_cache_async_readahead()源码也在mm/readahead.c文件中,异步提前读取
多个页面到内存中。 函数共6个参数,比page_cache_sync_readahead()多一个参数page。
1 |
|
若不需要预读或者页面处于回写状态,就直接返回。通过前面的检查后,就清除页面PG_ read ahed。在执行预读前,还要检查当前磁盘I/O是否处于拥塞状态,若处于拥塞就不能再进行预读。接下来就调用ondemand_readahead()真正执行预读。
5.5 ondemand_readahead()预读算法
ondemand_readahead()函数实现在文件mm/readahead.c。该函数主要根据file_ra_state描述符中的成员变量来执行一些动作。
(1)首先判断如果是从文件头开始读取的,初始化预读信息。默认设置预读为4个page。
(2)如果不是文件头,则判断是否连续的读取请求,如果是则扩大预读数量。一般等于上次预读数量x2。
(3)否则就是随机的读取,不适用预读,只读取sys_read请求的数量。
(4)然后调用ra_submit提交读取请求。
1 |
|
get_init_ra_size()计算初始预读窗口大小,get_next_ra_size()计算下一个预读窗口大小。
当进程第一次访问文件并且请求的第一个页面在文件内的偏移量是0时, ondemand _readahead()函数会认为进程会进行顺序访问文件。
于是函数从第一个页面开始创建新的当前窗口。当前窗口的初始值大小一般是2的幂次方,通常与进程第一次读取的页面数有关:请求的页面数越多,当前窗口越大,最大值保存在ra->ra_pages中。
相反地,进程第一次访问文件,但请求的页面在文件内的偏移量不是0时,内核就认为进程不会进行顺序访问。这样暂时关闭预读功能(设置ra->size的值为-1)。
然而内核重新发现顺序访问文件时,就会启用预读,创建新的当前窗口。若前进窗口(ahead window)不存在,当函数意识到进程在当前窗口进行顺序访问时,就会创建新的前进窗口。前进窗口的起始页面通常是紧邻当前窗口的最后一个页面。前进窗口的大小与当前窗口大小有关。一旦函数发现文件访问不是顺序的(根据前一次的访问),当前窗口和前进窗口就会被清空且预读功能被暂时关闭。当发现顺序访问时,就会重新启用预读。
ra_submit()仅是对__do_page_cache_readahead()的封装。
5.6 __do_page_cache_readahead()
__do_page_cache_readahead()有4个参数:
mapping:文件拥有者的addresss_space对象
filp:文件对象 offset:页面在文件内的偏移量
nr_to_read:完成当前读操作需要的页面数
lookahead_size:异步预读大小
1 |
|
在从磁盘上读数据前,首先预分配一些内存页面,用来存放读取的文件数据。在预读过程中,可能有其他进程已经将某些页面读进内存,检因此在此检查页面是否已经在Cache中。若页面Cache中没有所请求的页面,则分配内存页面,并将页面加入到页面池中。 当分配到第nr_to_read ‐ lookahead_size个页面时,就设置该页面标志PG_readahead,以让下次进行异步预读。 页面准备好后,调用read_pages()执行I/O操作,从磁盘读取文件数据。
5.7 readpages
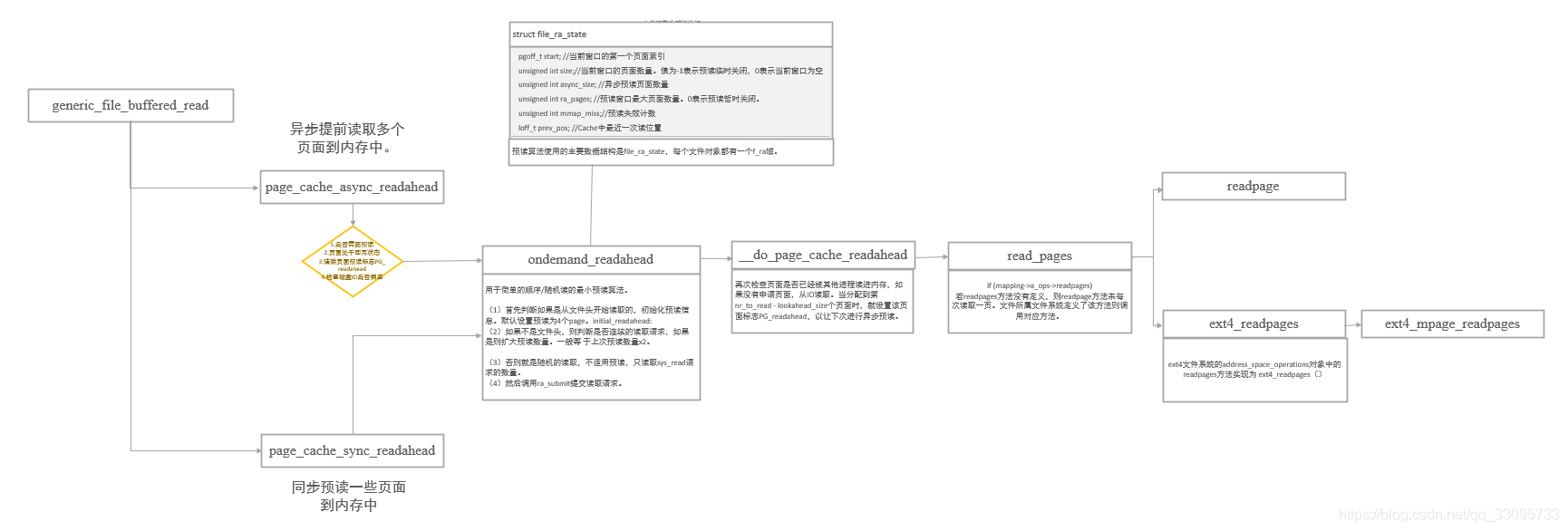
ext4文件系统的address_space_operations对象中的readpages方法实现为 ext4_readpages()。若readpages方法没有定义,则readpage方法来每次读取一页。从方法名字,我们很容易看出两者的区别,readpages是一次可以读取多个页面,readpage 是每次只读取一个页面。两个方法实现上差别不大,我们以ext4文件系统为例,只考虑readpages方法。 ext4_readpages()在文件fs/ext4/inode.c中。
1 |
|
整个函数调用流程如下图所示。
参考内容:
https://blog.csdn.net/jinking01/article/details/107221428
https://www.usenix.org/legacy/publications/library/proceedings/usenix2000/freenix/full_papers/silvers/silvers_html/index.html
http://www.ilinuxkernel.com/files/Linux.Kernel.Cache.pdf


