1.前言
进程的定义非常简单:进程就是运行中的程序。程序本身没有生命周期,它只是存在磁盘上面的一些指令或者静态数据。这些字节需要操作系统的帮助运行起来,发挥其应该有的作用。
我们在使用计算机的时候,会喜欢一边听着音乐,一边玩着游戏,这样是没问题的,我们的操作系统可能有上百个进程在同时运行。但是我们的硬件资源是有限的,假设一个计算机只有一个CPU(实际上也不会太多),成百个进程都在运行着,那CPU应该给谁用呢?操作系统就创造了一个美丽的假象-虚拟化CPU,将一个物理CPU虚拟成多个虚拟CPU分给每一个进程使用,因此每一个进程都以为自己在独占CPU。
2.如何提供有许多CPU的假象?
通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟CPU的假象。这叫做时分共享CPU技术。那么操作系统如何完成这一切功能。
2.1 操作系统是管理多个进程执行的软件
简单来看,操作系统就是一组系统调用API。进程执行系统调用,会使用指令(syscall)回到操作系统的代码执行,当然这就属于进程主动的触发中断;除此之外,还有硬件中断(时钟,I/O设备),对于一个进程来说,是被动发生的。
假设以两个程序qq和微信为例,在最开始的时候肯定执行的操作系统程序。将物理内存分别分一部分给微信、qq和内核,我们上面说了进程是运行的程序,其是动态变化的,也就是包含其占有的内存和寄存器,里面存储了当前进程的状态。操作系统代码执行一段时间以后,加载微信程序,也就是恢复它的内存和寄存器状态,让其在CPU上运行,这一过程通过iret中断指令完成。接下来执行权就到了微信进程,也叫做用户态。当然当前进程不能无限执行下去,通过一次中断或者系统调用,会再次执行os代码,os会负责保存微信进行的执行现场也就是内存和寄存器信息。最后再次加载qq程序,一直这样切换执行下去。操作系统始终在内核态运行,而应用程序始终在用户态运行。正是通过这些切换,操作系统实现了对CPU的虚拟化,当某个应用程序运行的时候它感觉到的就是现在它独占了CPU资源。

3.操作系统提供哪些系统调用API?
上面提到了一个进程可以主动放弃自己的执行权,也是就通过系统调用,将执行权交还给操作系统。那么操作系统内核都提供了哪些系统调用来管理进程?主要有创建(fork)、替换执行(execve)、删除(exit)。
3.1创建(fork)
为什么需要这么一个系统调用呢,因为我们的系统在最开始启动后并不会有太多的进程,需要有一个系统调用能够在接下来的使用中创建更多的进程。例如我们的shell,可以在shell中使用命令创建一个进程。
fork就像一把叉子,主要完成
- 做一份进程完整的复制(内存、寄存器运行现场)
- 父进程返回子进程的pid,子进程返回0

那么创建一个进程为什么要叫做叉子呢?还是以我们刚才的qq进程为例,如果它调用了fork系统调用就会在当前系统中多出一个进程,而这个进程是之前qq进程的拷贝,它包括几乎所有的进程当前的状态(除了返回值pid),包括内存、寄存器。原来的进程也叫父进程和新创建的进程也叫子进程都可以继续向下执行,所以说它像一个叉子,走着走着就分了个叉。父进程返回值是子进程的pid,子进程的返回值是0。

3.2 直面fork
下面通过两个小实验,来看一下fork究竟是如何工作的。
3.2.1 实验一
1 | 1 |
根据父进程返回子进程的pid,子进程返回0,我们可以对上面的程序进行画图分析,括号中的内容用于记录三个变量的值和接下来要执行的PC指令,~代表目前未知的变量值,(pid1,pid2,pid3,PC)。程序执行完,一共会有八个进程对printf语句进行输出。红色标出的便是最终的结果。

下面运行程序,查看实际的运行结果,结果和上面画图分析的结果是一致的,共有八种不同的结果输出。做完该实验就能理解子进程是父进程的一个拷贝,其中黑色标注出的0和FORK2_PID都会一直传递下去,并且fork会返回不同的函数值给父子进程。

3.2.2 实验2
1 | 1 |
程序的执行流程如下:

可以看到程序会打印出六个Hello world,我们执行程序结果也是一样的。

似乎毫无疑问,现在将输出结果重定向到一个文件中。

重定向输出结果到一个txt文件后,发现比刚才控制台多了两个输出。这是为什么呢?
原因就在于printf函数,printf函数在标准输出为控制台的时候会直接输出,但是当标准输出是一个文件的时候,printf会将结果暂存在缓冲区中,在第二次fork的时候,毫无疑问,缓冲区中的hello world 也被拷贝了一份,如下图所示,因此最终文件中就包含了8个Hello world。

3.3 execve系统调用
除了能够对进程进行创建,还需要能够执行别的程序,execve系统调用就是这样一个功能,将当前运行的进程“替换”成另一个程序,从头开始执行。fork以后得到的进程是与父进程相同的,但是跟多的时候我们创建子进程是为了让他执行不同的程序,去做别的工作。execve就是启动一个新程序的系统调用。exec函数一共有六个,其中execve为内核级系统调用,其他(execl,execle,execlp,execv,execvp)都是调用execve的库函数。
1 | execve(filename,argv,enpv) |
一个进程调用execve以后,它没有创建新的进程,而是从传入的可执行程序中加载代码和静态数据,并用它覆写自己的代码段、堆、栈,以及其他内存空间也会被重新初始化。然后操作系统就执行该程序。所以对execve的成功调用永远不会返回,只有在发生错误的时候才会返回-1,从原程序的调用点接着往下执行。
1 | arch/i386/kernel/process.c |
regs.ebx存储的是需要调用的程序名称,也就是第一个参数,使用getname 将该字符串从用户空间拷贝到系统空间。接下来就调用do_execve完成其主体功能。
1 | fs/exec.c |
使用 open_exec找到并打开可执行程序的文件,接下来就需要装载可执行程序了,内核中为可执行程序的装入提供了一个数据结构linux_binprm,以便于存储和组织可执行程序中的信息。
1 | source/include/linux/binfmts.h#L22 |
函数open_exec()返回一个file结构指针,代表着读入可执行文件的上下文,所以将其保存在数据结构 bprm中。
最后的准备工作就是把执行的参数,也就是 argv[],以及运行的环境,也就是envp[],从用户空间拷贝到数据结构 bprm 中。其中的第1个参数 argv[0]就是可执行文件的路径名,已经在 bprm.filename中了,所以用copy_strings_kernel()从系统空间中拷贝,其它的就要用copy_strings()从用户空间拷贝。最后就到了关键的函数 search_binary_handler(),该函数就负责具体的装入和执行。
3.4 exit系统调用
上面介绍了可以使用fork创建一个进程,然后使用execve将该进程替换为任意一个程序,显而易见还缺少一个销毁进程的系统调用,才能完整的运转整个流程。
常用的C库函数void exit(status)
- 可以传入一个状态码status,0表示正常退出,其他表示非正常退出,一般都用-1或者1,标准C里有EXIT_SUCCESS和EXIT_FAILURE两个宏。
- 父进程可以使用wait系统调用接受子进程的返回值,从而针对不同的情况进行处理。
除了上面的exit函数,exit还有其他几种形态,_exit(0 ),SYS_exit。
通过一个程序看一下他们的区别:
1 |
|
结果如下

不传入参数调用exit(0),会执行func输出字符串,其余两个都不会执行atexit注册的func,没有任何输出。因为前者是libc的库函数,后两者是系统调用,看不到libc的atexit函数。
使用strace分别跟踪后两个程序,发现_exit最终调用了exit_group(0),会终止进程中的所有线程。

SYS_exit最终调用了exit(0),只会终止当前的线程。

exit的几种形态
- exit(0) - stdlib.h中声明的 libc函数,会调用atexit,上面介绍的函数。
- _exit(0) - glibc的syscall wrapper
- 执行“exit_group”系统调用终止整个进程(所有线程)
- 不会调用atexit
- syscall(SYS_exit,0)
- 执行“exit”系统调用终止当前线程,不会调用atexit
4.处理器调度
通过前面已经了解到了,操作系统通过分时,实现了CPU的虚拟化。在中断发生以后,返回之前,操作系统一定要选择一个进程进行执行,那么这里就有了一个问题。
4.1中断以后选择哪个进程在处理器上执行?
选择哪个进程在处理器上运行,就是调度的概念,调度的实质就是资源的分配。操作系统考虑了不同的算法来实现资源的分配,而且一个好的调度算法应该考虑以下几个方面:
- 公平:保证每个进程得到合理的CPU时间
- 高效:使CPU保持忙碌状态
- 响应时间:使交互响应时间尽可能短
- 周转时间:等待输出的时间尽可能短
- 吞吐量:单位时间内处理的进程数量尽可能多
显然不可能有算法同时达到这五个目标,不同的操作系统会有不同的取舍。
常见的调度算法有:
- 时间片轮转调度算法
- 优先权调度算法
- 多级反馈队列调度算法
- 实时调度
- 完全公平调度算法
4.2Linux系统中进程的组织方式
一个系统中通常有成百上千的进程,相应的就有这么多的PCB,为了有效的进行管理,就必须用适当的方式将他们组织起来。
组织方式主要包括:
- 进程链表
- 哈希表
- 就绪队列
- 等待队列
4.3实际Linux内核的调度算法是如何取舍的?
Linux 2.4中使用goodness()函数,给每个处于可运行状态的进程赋予一个权值(Weight),使用这个权值衡量一个处于可运行状态的进程值得运行的程度。调度程序以这个权值作为选择进程的唯一依据。
虽然Linux2.4进程调度程序简单有效,但是也有其缺点。
- 单个就绪队列问题,时间片耗尽的进程依然会放进同一个就绪队列中,在不可被调度的情况下,还会参与调度。
- 多处理器问题,多个处理器上的进程放在同一个就绪队列中,因而调度器对它的所有操作都会因全局自旋锁而导致系统各个处理机之间的等待,使得就绪队列成为一个明显的瓶颈。
- 内核不可抢占问题,如果某个进程,一旦进了内核态那么再高优先级的进程都无法剥夺,只有等进程返回内核态的时候才可以进行调度。缺乏对实时进程的支持。
针对以上问题,Linux 2.6做了较大的改进。针对多处理器问题,为每个CPU设置一个就绪队列。针对单就绪队列问题,设置两个队列组,即active队列组和expired队列组。借助以上队列实现了时间复杂度为O(1)的调度算法。直到Linxu 2.6.23内核版本中,O(1)调度算法才真正替代为CFS(完全公平)调度算法。
4.3.1 就绪队列
O(1)调度器是以进程的动态优先级prio为调度依据的,它总是选择目前就绪队列中优先
级最高的进程作为候选进程 next。由于实时进程的优先级总是比普通进程的优先级高,故能
保证实时进程总是比普通进程先被调度。
Linux2.6 中,优先级 prio 的计算不再集中在调度器选择 next 进程时,而是分散在进程
状态改变的任何时候,这些时机有:
- 进程被创建时;
- 休眠进程被唤醒时;
- 从TASK_INTERRUPTIBLE 状态中被唤醒的进程被调度时;
- 因时间片耗尽或时间片过长而分段被剥夺 CPU 时;
在这些情况下,内核都会调用 effective_prio()重新计算进程的动态优先级 prio并根据计算结果调整它在就绪队列中的位置。
Linux 2.6为每个cpu定义了一个struck runqueue数据结构,每个就绪队列都有一个自旋锁,从而解决了 2.4 中因只有一个就绪队列而造成的瓶颈。
1 | struct runqueue { |
active 是指向活动进程队列的指针;expired 是指向过期进程队列的指针;array[2]是实际的优先级进程队列,其中一个是活跃的一个是过期的,过期数组存放时间片耗完的进程。
每个处理器的就绪队列都有两个优先级数组,它们是 prio_array 类型的结构体。Linux2.6
内核正是因为使用了优先级数组,才实现了 O(1)调度算法。该结构定义在 kernel/sched.c 中:
1 | struct prio_array{ |
4.3.2 调度算法介绍
选择并运行候选进程,确定next,下一个应该占有 CPU 并运行的进程,schedule()函数是完成进程调度的主要函数,并完成进程切换的工作。schedule()用于确定最高优先级进程的代码非常快捷高效,其性能的好坏对系统性能有着直接影响,它在/kernel/sched.c 中的定义如下:
1 | ... |
其中,sched_find_first_bit()能快速定位优先级最高的非空就绪进程链表,运行时间和就绪队列中的进程数无关,是实现O(1)调度算法的一个关键所在。
schedule()的执行流程:
首先,调用 pre_empt_disable(),关闭内核抢占,因为此时要对内核的一些重要数据结构进行操作,所以必须将内核抢占关闭;其次,调用sched_find_first_bit()找到位图中的第1个置1的位,该位正好对应于就绪队列中的最高优先级进程链表;
再者,调用 context_switch()执行进程切换,选择在最高优先级链表中的第 1个进程投入运行;
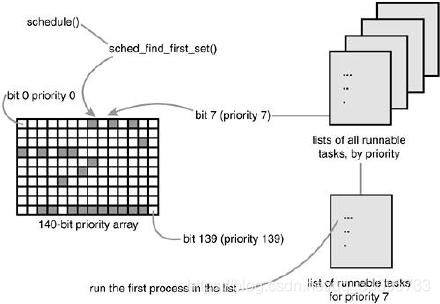
图中的网格为 140 位优先级数组,queue[7]为优先级为 7 的就绪进程链表。此种算法保证了调度器运行的时间上限,加速了候选进程的定位过程。
Linux2.4 调度系统在所有就绪进程的时间片都耗完以后在调度器中一次性重新计算,其中重算是用for循环相当耗时。
Linux2.6 为每个 CPU 保留 active 和 expired 两个优先级数组, active 数组中包含了有剩余时间片的任务,expired 数组中包含了所有用完时间片的任务。
当一个任务的时间片用完了就会重新计算其时间片,并插入到 expired 队列中,当 active 队列中所有进程用完时间片时,只需交换指向 active 和 expired 队列的指针即可。此交换是实现 O(1)算法的核心,由 schedule()中以下程序来实现:
1 | array = rq ->active; |


