从Linux 2.6.32开始,Linux内核脏页回写通过bdi_writeback机制实现,bdi的全拼是backing device info(后端存储设备信息,如ssd、hdd)。用户态调用write系统调用写入数据后,文件系统只在页缓存中写入数据便返回了write系统调用,并没有分配实际的物理磁盘块,ext4称为延迟分配技术(delay allocation)。本文将介绍内核是在何时如何将写入的数据回写到磁盘。
核心数据结构初始化
回写机制借助了Linux中工作队列来完成,在内核启动的时候,系统会使用alloc_workqueue函数申请一个用于回写的工作队列。具体实现在函数default_bdi_init中。
1 | // /mm/backing-dev.c |
函数调用栈如下图。
bdi_init()函数初始化bdi (struct backing_dev_info),该结构体包含了块设备信息,代表一个设备。
- struct backing_dev_info:描述一个块设备。
- struct bdi_writeback:管理一个块设备所有的回写任务。
- struct wb_writeback_work :描述需要回写的任务。
还有管理回写任务的结构体bdi_writeback,描述任务的结构体wb_writeback_work,其三者的关系如下图所示。
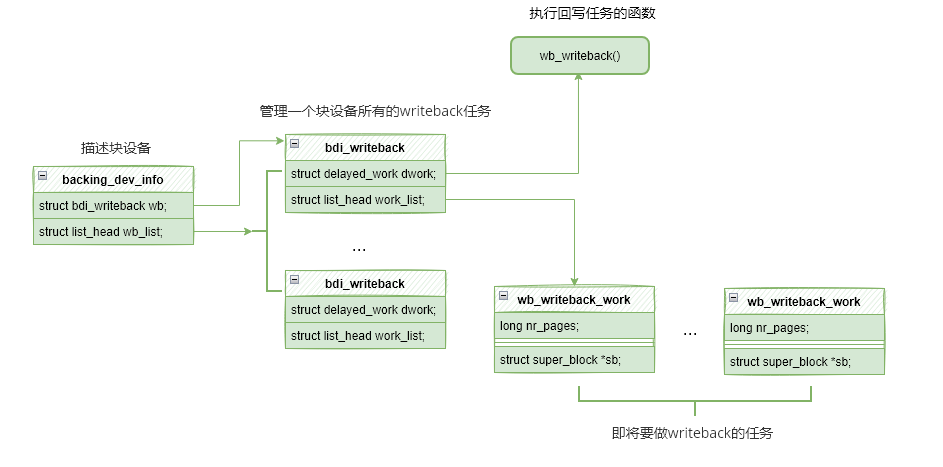
backing_dev_info中维护了wb_list链表,管理bdi_writeback,同时每个bdi_writeback中维护了dwork和work_list,前者代表处理任务的函数,后者则是任务列表。
在bdi_init中对bdi进行初始化后,会继续调用倒wb_init(),该函数对bdi中的wb(struct bdi_writeback)进行初始化。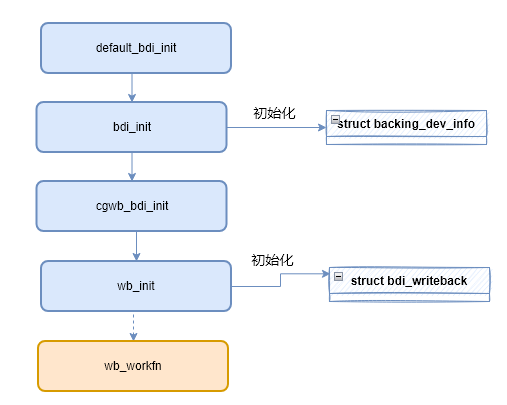
1 | // /fs/fs-writeback.c |
wb_init在初始化过程中,给wb->dwork字段赋值了函数wb_workfn,后面触发回写任务时,就会通过该函数进行执行回写。
1 | static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi, |
至此bdi_writeback机制初始化完成。
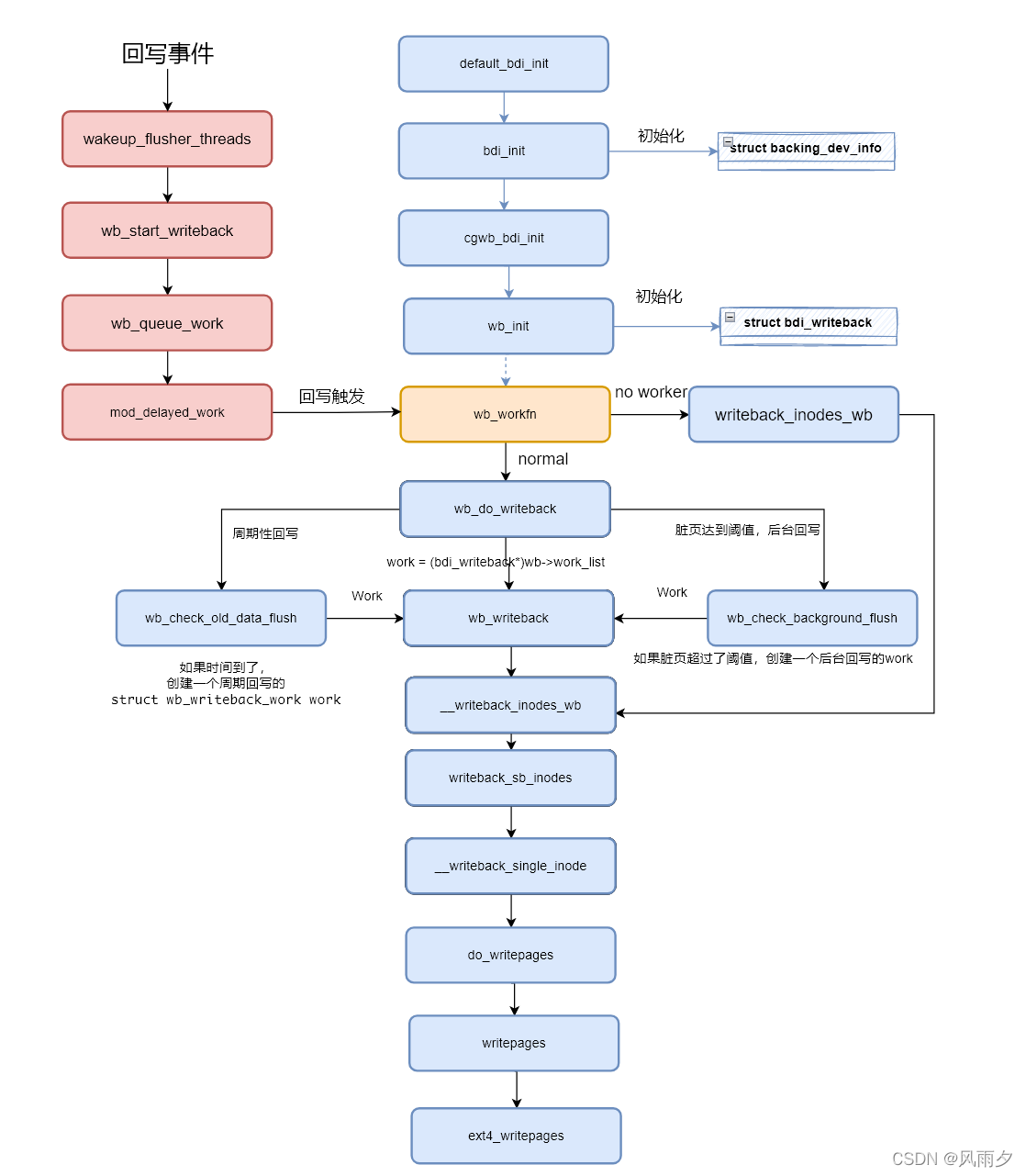
触发回写任务的时机
由于写入的数据都缓存在内存中,猜想当空闲内存紧张的时候,内核会执行回写任务。于是我们需要减少系统可用内存,使用如下命令在内存中创建文件系统然后往里面写入文件。
1 | mkdir tmp |
使用 dd 命令在该目录下创建文件。我们创建了一个79M的文件。
1 | dd if=/dev/zero of=tmp/file bs=1M count=79 |
完成上述操作以后系统还剩余2M内存,内核并没有立即触发回写,于是使用write系统调用继续向磁盘写入数据。
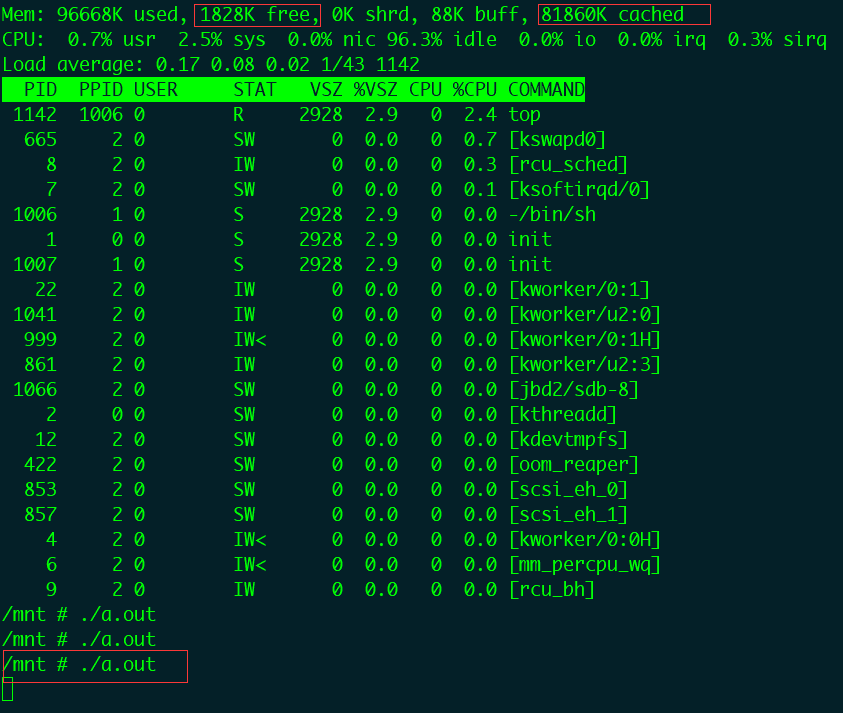
很快就触发了内核函数wakeup_flusher_threads(事先添加了断点),函数调用栈如下:
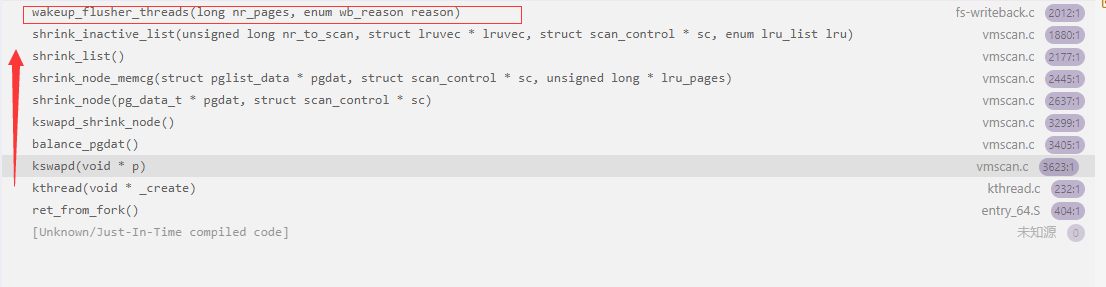
从内核函数调用栈来看是触发了kswapd内核线程的非活跃LRU链表回收。shrink_inactive_list函数扫描不活跃页面链表并且回收页面,调用了wakeup_flusher_threads函数进行回写操作。
函数代码如下,该函数遍历所有bdi设备下的writeback,并通过函数wb_start_writeback执行回写操作:
1 | /* fs/fs-writeback.c |
GDB查看传入wakeup_flusher_threads的参数值分别是nr_pages = 0和reason = WB_REASON_VMSCAN。
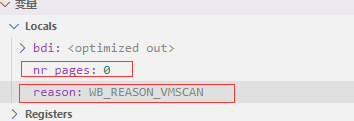
其中nr_pages等于0表示尽可能回写所有的脏页reason表示本次回写触发的原因。除了WB_REASON_VMSCAN,还定义了如下原因,如周期回写:WB_REASON_PERIODIC,后台回写:WB_REASON_BACKGROUND。
1 | /* |
我们继续分析wb_start_writeback回写函数。该函数创建并初始化了一个wb_writeback_work来描述本次回写任务,最后调用wb_queue_work。
1 | void wb_start_writeback(struct bdi_writeback *wb, long nr_pages, |
wb_queue_work调用mod_delayed_work将该任务挂入工作队列(workqueue),在等待delay时间后由工作队列的工作线程(worker)执行初始化时注册的任务管理函数wb->dwork。Linux workqueue如何处理work的过程可以参考文章,本文跳过该过程,直接到回写任务的处理函数wb_workfn继续分析:
http://www.wowotech.net/irq_subsystem/queue_and_handle_work.html
1 | static void wb_queue_work(struct bdi_writeback *wb, |
关于触发内核回写的函数调用总结如下图: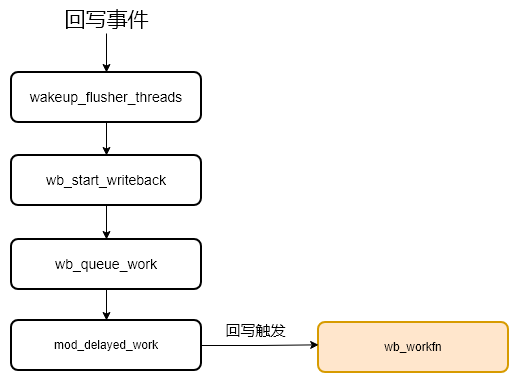
回写任务的执行
回写的执行在文件系统层的函数调用如下所示。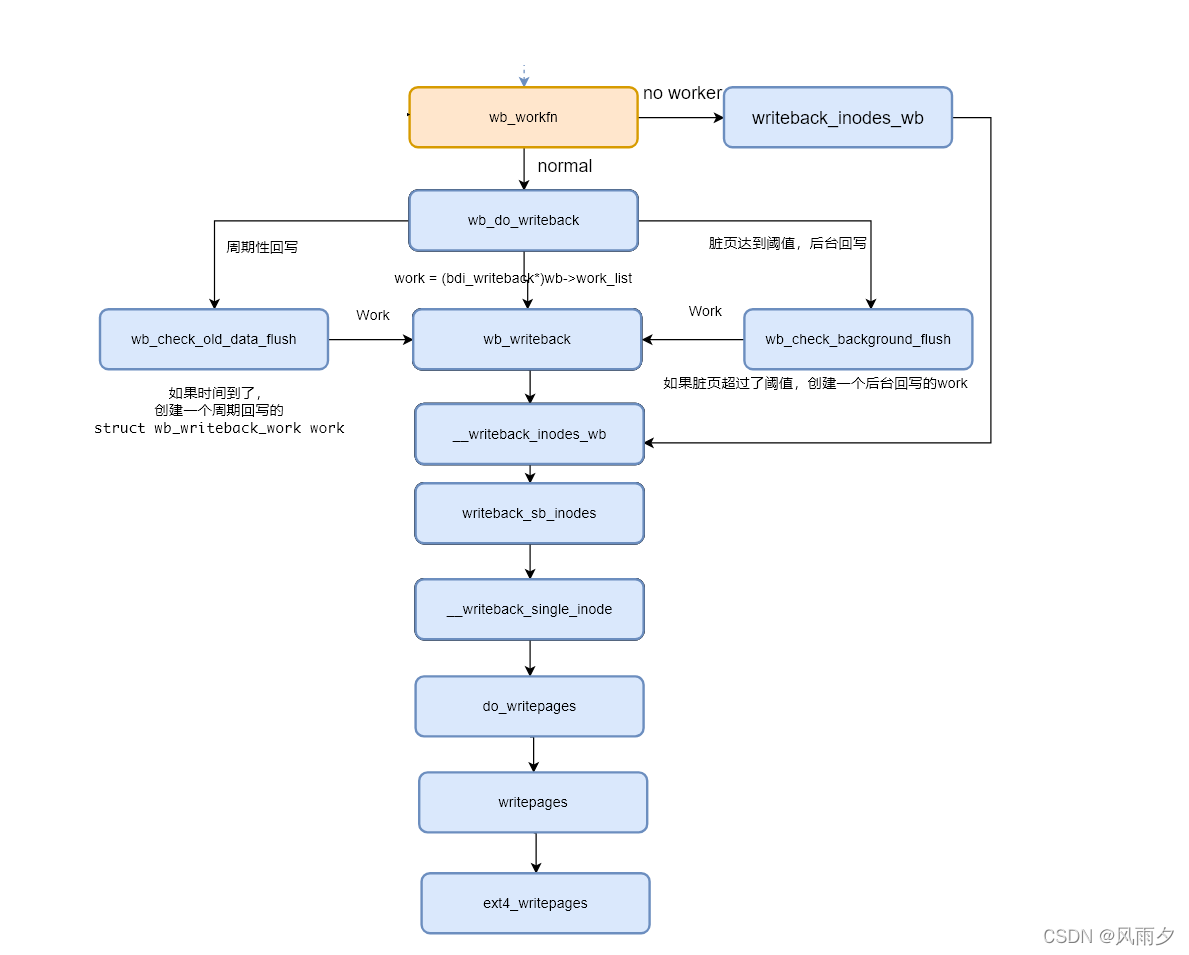
函数wb_workfn正常路径为遍历work_list,执行wb_do_writeback函数。如果没有足够的worker则执行writeback_inodes_wb函数回写1024个脏页。
1 | void wb_workfn(struct work_struct *work) |
wb_do_writeback函数在遍历wb并调用wb_writeback回写结束后会进行定时回写和脏页是否超过阈值的回写检查。
1 | /* |
wb_writeback根据是否包含superblock,分别调用writeback_sb_inodes和__writeback_inodes_wb。
1 | static long wb_writeback(struct bdi_writeback *wb, |
writeback_sb_inodes调用__writeback_single_inode。
1 | static long writeback_sb_inodes(struct super_block *sb, |
__writeback_single_inode调用do_writepages。
1 | static int |
do_writepages就出现了我们熟悉的页缓存函数操作集struct address_space_operations *a_ops。其中writepages函数在ext4中的实现为ext4_writepages。
1 | int do_writepages(struct address_space *mapping, struct writeback_control *wbc) |
接下来会在ext4_writepages中打包bio结构体,发送到通用块层,继续更底层的IO操作。
最后,bdi_writeback机制整体流程如下。