1. 简介
RCU (Read-copy update)是2002年10月添加到Linux内核中的一种同步机制。作为数据同步的一种方式,在当前的Linux内核中发挥着重要的作用。
RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。
RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。
2. 实现功能
RCU的实现主要解决了以下问题:
保证读取链表的完整性。新增或者删除一个节点,不至于导致遍历一个链表从中间断开。但是RCU并不保证一定能读到新增的节点或者不读到要被删除的节点。
在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作。RCU中把这个过程称为宽限期(Grace period)。
在读取过程中,另外一个线程插入了一个新节点,而读线程读到了这个节点,那么需要保证读到的这个节点是完整的。这里涉及到了发布-订阅机制(Publish-Subscribe Mechanism)。
2.1 数据完整性
2.1.1 插入数据时保证读取数据的完整性
如下图,在链表中加入一个节点new到A节点之前,所要做的第一步是将new的指针指向A节点,第二步才是将Head的指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步的时候,读线程如果读到new节点,也可以继续遍历链表。如果把这个过程反过来,第一步head指向new,而这时一个线程读到new,由于new的指针指向的是Null,这样将导致读线程无法读取到A,B等后续节点。因此RCU并不能保证在插入数据时读线程一定能够读到新数据。
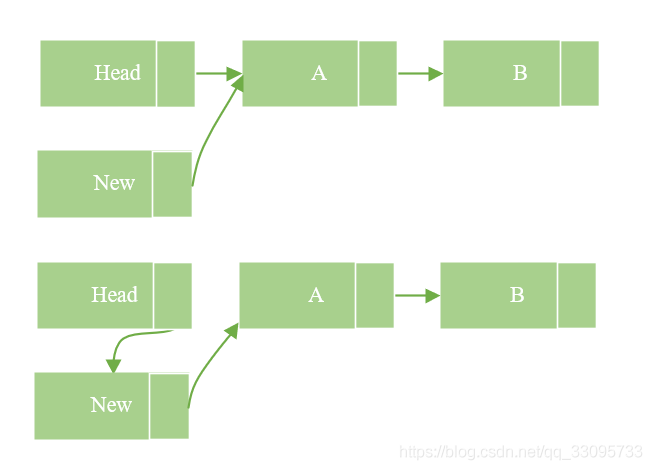
2.1.2 删除数据时保证读取数据的完整性
删除节点A时,首先将Head的指针指向B,保持A的指针,然后删除程序将进入宽限期检测。由于A的内容并没有变更,读到A的线程仍然可以继续读取A的后续节点。A不能立即销毁,它必须等待宽限期结束后,才能进行相应销毁操作。由于Head的指针已经指向了B,当宽限期开始之后所有的后续读操作通过Head找到B,而A已经隐藏了,后续的读线程都不会读到它。这样就确保宽限期过后,删除A并不对系统造成影响。
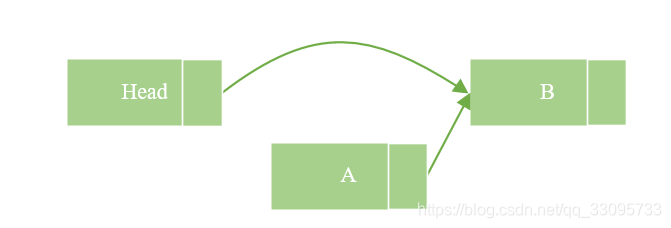
2.1.3 更新数据时保证读取数据的完整性
初始链表如下图所示,指针p指向的节点(5,6,7)是需要更新的节点,使用rcu更新节点代码如下:
1 | 1 q = kmalloc(sizeof(*p), GFP_KERNEL); |
为了简化操作使用了单向链表,节点的红色外框表示该节点有被引用,节点中的值表示变量a,b,c的值。
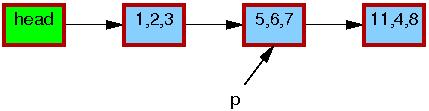
代码第一行申请内存并创建一个q节点。
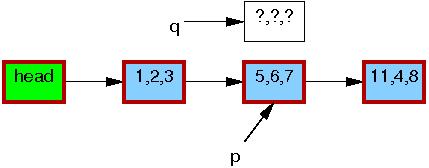
第2行将待更新节点p的数据复制到新节点q中。
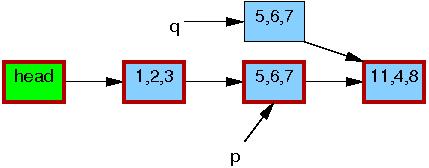
第3,4行更新节点q中b和c变量的值,将5,6,7改成5,2,3。修改完成之后,写线程就可以将这个更新“发布”了(publish),对于读线程来说就“可见”了。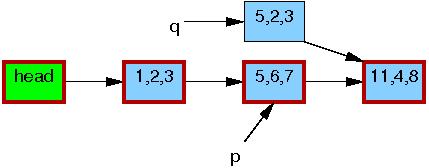
第5行进行替换,这样新节点q对读线程最终是可见的。如下所示,现在有了链表的两个路径。先前的读线程可能会看到5、6、7元素,但新的读线程会看到5、2、3元素。但是任何给定的读线程都保证读到完整的链表,而不是某个中间状态。
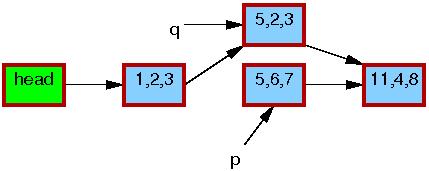
第6行synchronize_rcu()函数返回之后,一个grace period(宽限期)已经过去了,所以所有在list_replace_rcu()函数之前开始的读操作都已经完成了。任何读取5、6、7元素的读线程都被保证已经退出了它们的RCU读侧临界区,因此被禁止继续持有节点p的引用。,如下面的5、6、7元素周围的黑色细边框所示。就读线程而言,又回到了单一路径的链表同时更新了节点的数据。
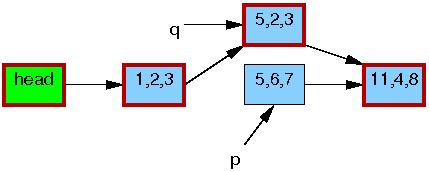
kfree()在第7行完成后,列表将显示如下:
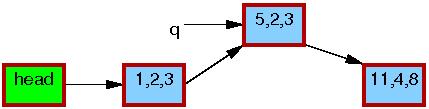
2.2 发布订阅机制
RCU的一个最关键的特性在于,它能够保证数据能安全的被多个线程同时读取,即便数据在同时更新。例如有全局指针gp,指向一段新的已分配内存并进行初始化。
1 |
|
由于编译器对代码进行优化,对于多CPU的机器来说,经常可能gp = p这个操作会发生在1,2或者3步之前,也就是说p还没被初始化完全就被赋值给了gp。rcu提供了一个具有发布含义的封装函数rcu_assign_ pointer() ,其封装了内存屏障功能,使用如下方式赋值。
1 |
|
这个函数能够发布(创建)一个新的结构体,保证从编译器和CPU层面上gp被赋值前,p指向的字段能够赋值完成。我们看看这个函数的具体实现(Linux kernel 4.11.4):
1 |
|
该段代码做了两件事:
- 在必要时插入一个内存屏障;
- 关闭编译器在赋值时的非顺序编译优化,保证赋值时已经初始化了。
保证赋值顺序执行后,还需要保证读的顺序性。有如下代码:
1 |
|
以上代码在一般的处理器架构没有问题,但在 DEC Alpha CPU机器上,编译器的 value-speculation 优化选项据说可能会“猜测” p1 的值,然后重排指令,fp->a,fp->b,fp->c会在p = gp还没执行的时候就预先判断运行,可能导致传入dosomething 的一部分属于旧的gbl_ foo,而另外的属于新的。这样导致运行结果的错误。
为了避免该类问题,RCU提供了原生接口rcu_dereference()来解决这个问题, rcu_dereference() 的实现,最终效果就是把一个受RCU保护的指针赋值给另一个,代码如下:
1 |
|
综上,rcu_assign_pointer是发布,而rcu_dereference是订阅。RCU还提供了一些更高级的API接口,如下:

2.3 RCU宽限期
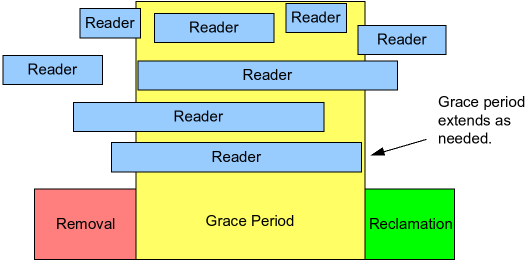
在RCU中,数据的删除和销毁需要一定的宽限期,主要是因为需要等待读线程的完成。如图所示:
有如下代码,两个线程同时运行 foo_ read和foo_update的时候,当foo_ read执行完赋值操作后,线程发生切换;此时另一个线程开始执行foo_update并执行完成。当foo_ read运行的进程切换回来后,运行dosomething 的时候,fp已经被删除,这将产生严重错误。
1 |
|
所以,写线程(删除和销毁数据的线程)在删除数据后不能立马销毁这个数据,一定要等待所有在宽限期开始前已经开始的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中宽限期左侧有三个reader在宽限期开始前已经开始了读取,必须等待他们结束,而最左侧的reader在开始宽限期之前就已经结束了读取,不需要考虑,其余在宽限期开始后才开始读取的reader不可能读取到旧的节点数据,因此也不需要考虑。
因此,RCU提供了一个接口函数synchronize_rcu()来同步在宽限期的读线程。只有宽限期中没有读线程了,这个函数才返回,也就是说这是一个阻塞函数。所以foo_update需要写成下面的形式才是安全的。
1 | void foo_update( foo* new_fp ) |
3. 总结
RCU的核心API如下:
1 | rcu_read_lock() |
其中,rcu_read_lock()和rcu_read_unlock()用来保持一个读者的RCU临界区.在该临界区内不允许发生上下文切换,内核要根据“是否发生过切换”来判断读者是否已结束读操作。
而下列的函数用于实现内存屏障的作用。
rcu_dereference():读者调用它来获得一个被RCU保护的指针。
rcu_assign_pointer():写者使用该函数来为被RCU保护的指针分配一个新的值。
synchronize_rcu():这是RCU的核心所在,它挂起写线程,等待读者都退出后释放老的数据。
参考链接:
https://lwn.net/Articles/262464/
https://www.cnblogs.com/schips/p/linux_cru.html


