1.概述
本文记录xv6操作系统的系统调用跟踪实验,xv6是一个类Unix的简单操作系统。该实验是要求实现一个trace系统调用,该系统调用的功能是根据用户传入的系统调用号跟踪某个或者某些进程的系统调用情况。
2. 实验要求
2.1 实验铺垫
有一个已给出的用户态trace.c程序如下:
1 |
|
该程序应该实现的执行效果如下:
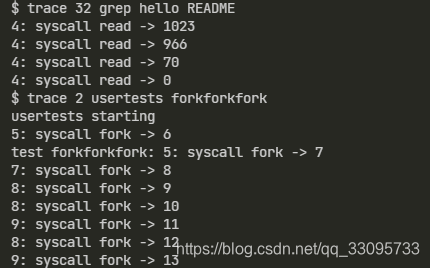
1 | $ trace 32 grep hello README |
命令格式为
$ trace
<command_args …>
syscall_num是系统调用号,command是待跟踪的程序,command_args是待跟踪程序的参数。例如上面的例子就是跟踪32号系统调用
输出的格式如下:
: syscall ->
pid是进程序号, syscallname是系统调用名称,returnvalue是该系统调用返回值,并且要求各个进程的输出是独立的,不相互干扰。
2.2 实验内容
- 用户态程序trace.c已经给出,需要我们实现对应的内核态程序trace系统调用(sys_trace)并添加进xv6系统。
- trace()函数传入了一个待跟踪的系统调用号,因为需要跟踪的系统调用是进程间独立的,因此sys_trace()系统调用应当实现功能:保存下这个待跟踪的系统调用号到当前进程(为trace.c程序创建的进程)。
- xv6中使用struct proc{}表示一个进程,在系统调用被触发的时候就可以根据proc中存储的系统调用号判断当前这个系统调用是不是需要进行跟踪。
- trac.c在运行待跟踪程序(如上文的grep命令)的时候并没有发生进程切换,这是将待跟踪系统调用号保存到当前进程(为trace.c程序创建的进程)proc中,并且能够在grep程序运行的时候从proc中取出系统调用号并捕获待跟踪系统调用(read)的关键。当进程调用exec函数时,该进程执行的程序完全替换为新程序,但是并不会创建新的进程,前后的进程id并未改变。exec只是用磁盘上的一个新程序替换了当前进程的代码段、数据段、堆、栈。
- 内核态系统调用入口程序syscall.c中判断当前进程proc中保存的待跟踪系统调用号是否与当前的系统调用号相同,如果相同则表示捕获到,输出进程id,系统调用函数名称,系统调用返回值。
3. xv6代码结构介绍
代码主要有三个部分组成:

- 第一个是kernel。我们可以ls kernel的内容,里面包含了基本上所有的内核文件。因为XV6是一个宏内核结构,这里所有的文件会被编译成一个叫做kernel的二进制文件,然后这个二进制文件会被运行在kernle mode中。

- 第二个部分是user。这基本上是运行在user mode的程序。这也是为什么一个目录称为kernel,另一个目录称为user的原因。
- 第三部分叫做mkfs。它会创建一个空的文件镜像fs.img,我们会将这个镜像存在磁盘上,这样我们就可以直接使用一个空的文件系统。
3.1 创建第一个进程
xv6运行在QEMU虚拟机中,QEMU仿真了RISC-V处理器。xv6的起始运行地址是0x80000000,当RISC-V仿真器启动时,它初始化自己并运行一个存储在只读内存中的引导加载程序(boot loader)。引导加载程序将xv6内核加载到内存中。然后,CPU开始在_entry(/kernel/entry.S)以machine mode执行xv6,此时还没有启用分页机制,虚拟地址直接映射到物理地址。
1 |
|
boot loader将xv6内核加载到物理地址0x80000000的内存中,地址区间0x0:0x80000000预留给IO设备。_entry中的指令设置了一个栈,用来运行C程序,随后调用了start函数(start.c)。
1 |
|
start函数执行了一些只允许在machine mode模式下的配置,然后转入supervisor mode,要进入supervisor mode,RISC-V 提供了指令 mret。它通过将main的地址写入寄存器mepc将返回地址设置为main,随后程序计数器指向main函数(kernel/main.c)
1 | // start() jumps here in supervisor mode on all CPUs. |
main函数初始化一些设备和子系统后,通过userinit()函数创建第一个进程,该进程执行了一段用户态汇编程序initcode.S,如下所示。使用exec系统调用将/user/init.c程序替换执行,Init()随后创建标准输入输出设备文件,启动一个shell程序,系统启动完成。
1 | # initcode.S |
3.2 系统调用
userinit()函数中调用的汇编代码initcode.S,所执行的exec是系统的执行的第一个系统调用。这个汇编程序中,它首先将init中的地址加载到a0(la a0, init),argv中的地址加载到a1(la a1, argv),exec系统调用对应的数字加载到a7(li a7, SYS_exec),最后调用ECALL。所以这里执行了3条指令,之后在第4条指令将控制权交给了操作系统。
userinit会创建初始进程,返回到用户空间,执行刚刚介绍的3条指令,再回到内核空间。查看系统调用处理函数syscall.c的代码。
1 |
|
num = p->trapframe->a7 会读取使用的系统调用对应的系统调用号。如果我们查看syscall.h,可以看到7对应的是exec系统调用。
1 | // System call numbers |
因此,这里实现的功能是告诉内核,某个用户应用程序执行了ECALL指令,并且想要调用exec系统调用。p->trapframe->a0 = syscallnum 这一行是实际执行系统调用。这里可以看出,num用来索引一个数组,这个数组是一个函数指针数组,可以想象的是syscalls[7]对应了exec的入口函数。
1 |
|
sys_exec中的第一件事情是从用户空间读取参数,它会读取path,也就是要执行程序的文件名。然后从用户空间将参数拷贝到内核空间。initcode.S完成了通过exec调用init程序。init会为用户空间设置好一些东西,比如配置好console,调用fork,并在fork出的子进程中执行shell。
1 | if(pid == 0){ |
4. 添加系统调用sys_trace
添加一个系统调用应该包含以下步骤:
在syscall.h中添加系统调用号
在系统调用入口函数sys_call.c增加sys_trace系统调用
添加一个entry到user/usys.pl。perl语言自动生成汇编语言usys.S,是用户态系统调用接口,首先把系统调用号压入a7寄存器,然后就直接ecall进入系统内核。而上文syscall函数就把a7寄存器的数字读出来调用对应的函数,所以这里就是系统调用用户态和内核态的切换接口。
1 | #usys.S |
- 添加声明到user/user.h,让程序在编译的时候可以通过。
- 添加系统调用号如下:
/kern/syscall.h
1 | // System call numbers |
- syscall.c增加sys_trace系统调用
/kern/syscall.c
1 | // 添加sys_trace声明 |
5. 实现跟踪打印系统调用
在sysproc.c中实现该系统调用处理函数
proc.h中为struct proc{}新增一个tracemask变量,用来保存当前进程要跟踪的系统调用号。
proc.c下的fork函数中实现子进程复制父进程tracemask功能。
syscall()系统调用入口分发函数,实现系统调用的跟踪。
添加$U/_trace到Makefile中的UPROGS变量里
- 实现系统调用处理函数
我们需要将用户态trace传入的待跟踪系统调用号绑定到当前进程的proc中,因此需要在struck proc中新增一个tracemask整型变量来保存用户态传入的系统调用号。
/kern/proc.h
1 |
|
通过函数argint()从a0寄存器中获取用户态传递的参数赋值给当前进程的tracemask,该参数是要跟踪的系统调用号。
/kern/sysproc.c
1 |
|
- 修改kernel/proc.c中的fork函数,添加子进程复制父进程mask的功能
/kern/proc.c
1 |
|
- syscall()函数中实现系统调用的跟踪
1 |
|
- 添加$U/_trace到Makefile中的UPROGS变量里,运行结果如下