预读算法
预读模式提高了Linux系统的读性能,但是在Android上直接使用传统的预读方案并不完全适用。
移动设备上的请求大小和页面缓存大小要小很多,可能导致降低预读效率,从而损害用户体验,比如很多预读的页面没有被使用,导致频繁的页面缓存回收,导致额外的延迟。
根据论文实验数据显示,传统的预读方案直接移植到移动设备,当预取100个页面到页面缓存时,平均大约有75个页面没有使用。
在当前的Linux内核中预读算法的不足:当一个请求属于顺序读操作时,将执行预读操作,预取大小为该读请求的2或4倍的页面。如果达到预读操作,预取页面的大小将增加上一次预读操作的2倍,直到达到预读的最大大小(默认128KB)。这种激进的预读方案会很快填满页面缓存。
预读算法主要功能和任务:
- 批量:把小I/O聚集为大I/O,改善利用率,提升系统的吞吐量
- 提前:对应用程序隐藏磁盘的I/O延迟,以加快程序的运行
- 预测:预读算法的核心,前两个功能的达成都依赖于准确的预测能力
文件预读算法的关键要点:
- 确定程序的访问模式,例如:顺序,逆序,随机。
- 应该动态确定预读的大小,过大会导致预读命中率的下降。一个程序要读的页面一般与已经读的页面呈现正相关,程序读粒度越大,它重复顺序读的可能性也越大。
- 异步预读,应当提前多长时间启动。
- 预读触发的条件:1.缓存缺失页面,进行同步预读。2.预读标记页面(PG_readahead page),进行异步预读。
- 非对齐读和重试读。
预读算法评价指标:
- 预读命中率:在所有被预读的页面中,被实际访问页面所占的百分比。
Linux页缓存涉及的重要数据结构与函数如下: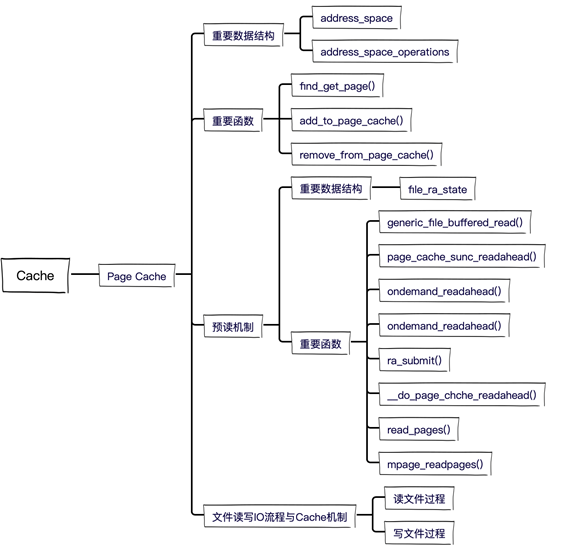
以ext4读操作为例,函数调用流程如下: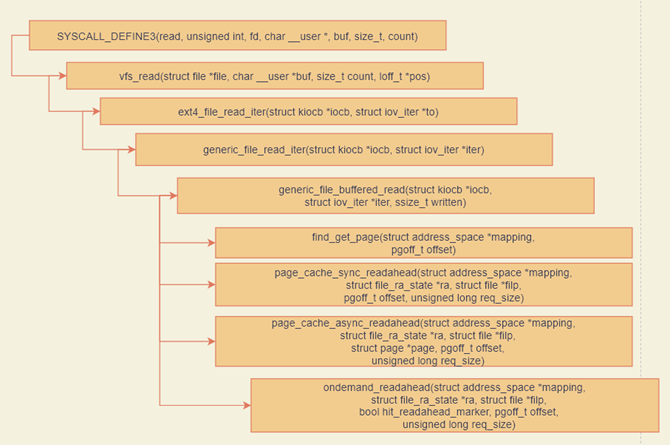
预读算法的设计权衡:
预读大小对I/O性能有很大影响,在确定预读大小值时,必须在吞吐量和延迟、预读命中率之间、page cache利用率进行权衡。
针对冷热文件数据,优化数据预取,将热数据尽可能地预读到page cache中,会大大提高page cache的命中率,相对于冷数据角度而言也提高了page cache的利用率。如果尽可能地预读热数据文件页,由于移动设备上的请求大小和页面缓存大小要小很多,可能有很有很多热数据页没有用到,反而降低了page cache的利用率。
缓存写入操作
调用块设备的write_begin函数,获取块设备缓存page;
调用iov_iter_copy_from_user_atomic将用户要写的用户空间的数据copy到块设备的缓存page中;
调用块设备的writer_end函数,在第2步骤已将用户数据copy到块设备的缓存page中,writer_end函数作用就是标记该page为最新、page_bh为dirty,等待在合适的时机被刷到设备中。
1 | //缓存写具体实现 |
在balance_dirty_pages_ratelimited里面,发现脏页的数目超过了规定的数目,就调用balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。
触发回写的场景还有:
- 用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页;
- 当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
- 脏页已经更新了较长时间,时间上超过了设定时间,需要及时回写,保持内存和磁盘上数据一致性。
块设备的writer_begin函数是blkdev_write_begin, 该函数为块设备的缓存准备page。
1 |
|
1 | int __block_write_begin_int(struct page *page, loff_t pos, unsigned len, |
块设备的writer_end函数是blkdev_write_end,在第2步骤已将用户数据copy到块设备的缓存page中,blkdev_write_end函数作用就是标记该page为最新、page bh为dirty,等待在合适的时机被刷到设备中。
缓存读取操作
在generic_file_buffered_read函数中,首先在page cache里寻找是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在page_cache_sync_readahead函数中实现。预读完了以后,再一次查找缓存页。
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
1 | static ssize_t generic_file_buffered_read(struct kiocb *iocb, |
回收算法
直接回收
空闲空间不够当前分配时触发,同步回收,停止内存分配。可能触发数据回写操作,系统开销大。
kswapd周期回收
异步回收,可与内存分配同时进行空闲页数量低于阈值时回收。最大的回收可能达到几千页。
内存回收方案与手机应用的特性不匹配。表现在以下两个方面:
- 回收的尺寸太大,尺寸是指每个回收操作释放的页数。
快速回收
直接回收
空闲空间不够当前分配时触发。可能触发刷新操作。系统开销大。kswapd
空闲页数量低于阈值时回收。最大的回收可能达到几千页。
- 有限的回收区域加重了这种惩罚。回收区域指回收操作释放的页面区域,例如inactive_file_lru链表中的页面。
根据页面类型分类的lru链表还有:
LRU_INACTIVE_ANON:不活跃匿名页面链表
LRU_ACTIVE_ANON:活跃匿名页面链表
LRU_INACTIVE_FILE:不活跃文件映射页面链表
LRU_ACTIVE_FILE:活跃文件映射页面链表
LRU_UNEVICTABLE:不可回收页面链表
缺页产生的原因
- 第一次读取某个页,并没有分配物理内存。
- 读取一个错误的页,进程会被杀死。
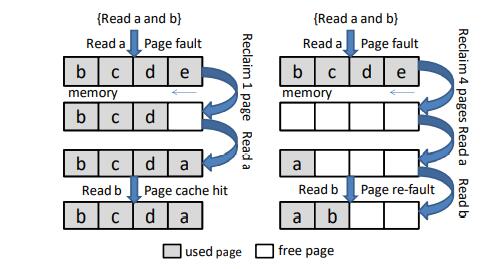
- 读取一个被回收的页,请求的页面一直在内存中,但是被回收算法回收了。页面二次缺页率表示在被回收的所有页面中重新发生缺页的比例。
影响性能的因素
二次缺页
二次缺页受可用内存的大小影响。直接回收
在页面分配过程中,当没有足够的可用空间来满足系统需求时会触发该方案。一旦触发直接回收,Android系统需要暂停分配过程,导致额外的性能下降。
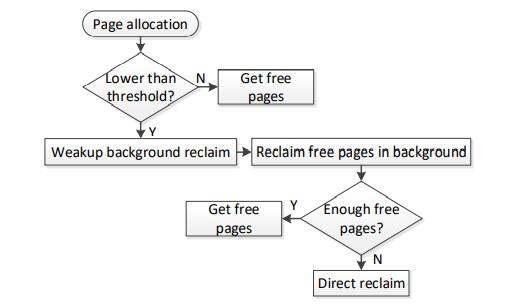
直接回收取决于可用内存大小和后台异步回收的延迟。
后台应用程序不会对用户体验产生影响,但也在继续申请空闲空间。
由于匿名页包含与进程关联的堆信息,因此这些匿名页被认为比文件页对进程更重要。大多数情况下,ACTIVE_ANONAME列表中的页面不会被逐出,即使它们属于后台应用程序。因此,后台应用程序的许多匿名页保留在存储器中,而来自前台应用程序的文件页被逐出。这些从前台应用程序逐出的文件页面可能很快会再次被访问,从而导致大量页面重新错误。此外,后台应用程序的匿名页面会占用空闲空间,从而影响直接回收的频率。kswapd后台回收通常大于32个页,而Android系统申请页通常小于16个页。最终为每个小的分配进行较大的回收,导致回收十分激进。较大的回收大小会延长后台回收的延迟,进而影响直接回收的频率,此外回收较大的粒度会导致更多不必要的refault。
解决思路
- 在回收文件页之前考虑先回收后台进程使用的匿名页,因为前台进程在用户体验上来说比后台进程要重要。
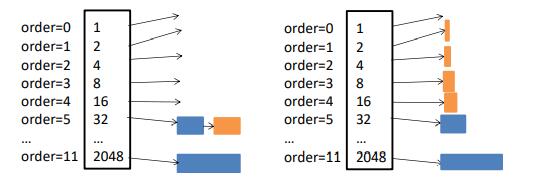
- 降低伙伴算法的阶数,移动设备最大的请求阶数为8,可以将order降低到9。降低拆分大空间的操作的次数。